
This article explains what Net Present Values, Face Values, Maturities, Coupons, and risk-free rates are, how to calculate them mathematically and compute them, and how they are used in excess returns using only Zero-Coupon Bonds; other types of bonds are discussed for completeness, but they will only be investigated as such in further articles to come. It is aimed at academics from undergraduate level up, and thus will explain all mathematical notations to ensure that there is no confusion and so that anyone - no matter their expertise on the subject - can follow.
One may find many uses for the methods outlined below. For example: To calculate metrics such as the Sharpe-Ratio, one needs first to calculate excess returns, that then necessitates the calculation of risk-free rates of return.
Using this Site
You may use the links below to reach out to contents, and scale up or down the math figures at your convenience as per the below.
Content
- Use of Government Bonds in calculating risk-free rates
- 1. YTM implied daily risk-free rate
- US Treasury Securities: Generalised
- T-bill Example 1: One-month T-Bill
- T-bill Example 2: Three-Month T-Bill with Monthly Compounding
- Risk-free rate of a One-Month T-Bill
- Getting to the Coding
- Create a function to compute the risk-free rate of return for any Zero-Coupon Bond's Yield To Maturity gathered from Datastream
- 2. Risk-free rate based the change in the same bond's market value from one time period (e.g.: day) to the next
- Excess Returns
- Conclusion
- References
Only certain banks have access to the primary sovereign bond markets where they may purchase Domestic Sovereign/Government Bonds. There are many such types of bonds. Among others, there are:
- United States (US): US Treasury securities are issued by the US Department of the Treasury and backed by the US government.
- Fixed principal: A principal is the amount due on a debt. In the case of bonds, it is often referred to as the Face Value. The Face Value of all US Treasury securities is 1000 US Dollars (USD)
- Treasury‐bills (as known as (a.k.a.): T-bills) have a maturity of less than a year (< 1 yr). These are bonds that do not pay coupons (Zero-Coupon Bonds).
- Treasury‐notes (a.k.a.: T‐notes) have a maturity between 1 and 10 years (1‐10 yrs).
- Treasury-bonds (a.k.a.: T‐bonds) have a maturity between 10 and 30 years (10‐30 yrs). It is confusing calling a sub-set of bonds 'T-bonds', but that is their naming conventions. To avoid confusion, I will always refer to them explicitly as Treasury-bonds (or T‐bonds), not just bonds.
- Inflation‐indexed: TIPS
- Treasury STRIPS (created by private sector, not the US government)
- Fixed principal: A principal is the amount due on a debt. In the case of bonds, it is often referred to as the Face Value. The Face Value of all US Treasury securities is 1000 US Dollars (USD)
- United Kingdom: Since 1998, gilts have been issued by the UK Debt Management Office (DMO), an executive agency of the HMT (Her Majesty's Treasury).
- Conventional gilts: Short (< 5 yrs), medium (5‐15 yrs), long (> 15 yrs)
- Inflation‐indexed gilts
- Japan
- Medium term (2, 3, 4 yrs), long term (10 yrs), super long term (15, 20 yrs)
- Eurozone government bonds
There are several ways to compute risk-free rates based on bonds. In this article, we will focus on T-bills, as US Sovereign Bonds are often deemed the safest (which is a reason why the USD is named the world's reserve currency) and T-bills are an example of Zero-Coupon Bonds (as per the method outlined by the Business Research Plus). From there, a risk-free rate of return can be computed as implied by its bond's Yield To Maturity and based the change in the same bond's market price from one day to the next.
A bond is a debt; a debt with the promise to pay a Face Value (FV) in m years (m for maturity) in the future as well as Coupons (summing to C every year) for an amount today. That latter amount paid for the bond may be fair; a fair value for a bond is calculated as its Net Present Value (NPV) such that, at time t:
where YTM is the annualised Yield To Maturity of the Bond in question and facf is the annual compound frequency (such that if we compound cash flows annually, facf=1; and if we compound cash flows bi-annually (i.e.: twice a year / every 6 months), facf=0.5).
Sub-Annual Interpolation of YTMs
Note that when using YTM values inter-year (e.g.: after 6 month), we then use a fraction of it, i.e.: facf YTM. This is because all YTM values are annualised and - in accounting standards - sub-annual interpolation of YTMs are always linear/arithmetic. It must be remembered - however - that super-annual (i.e.: more than a year) extrapolation of YTMs are not necessarily linear/arithmetic.
Compounding
It follows from the above that if facf=1 such that we use an annually compounding accounting method, annual extrapolation of YTMs are geometric.
Since Coupons are most often paid bi-annually, it is common standard to compound cashflows bi-annually too when they involve Bonds - as aforementioned. This is done to model a Bond-holding-agent) who re-invests Coupon payments as soon as they're received. In this scenario, facf=facpf=0.5.
Discount Factor
It is easy to see that NPVs and YTMs are therefore (inversely) related; if one changes, the other must change too. We may - therefore - equivalently speak about a change in NPV and a change in YTM since the FV (for each sovereign bond issuer) does not change. The YTM acts as the discount factor here; as a matter of fact, we can see that the YTM is the annual growth rate of our NPV that leads it to the FV in the following:
Comparability
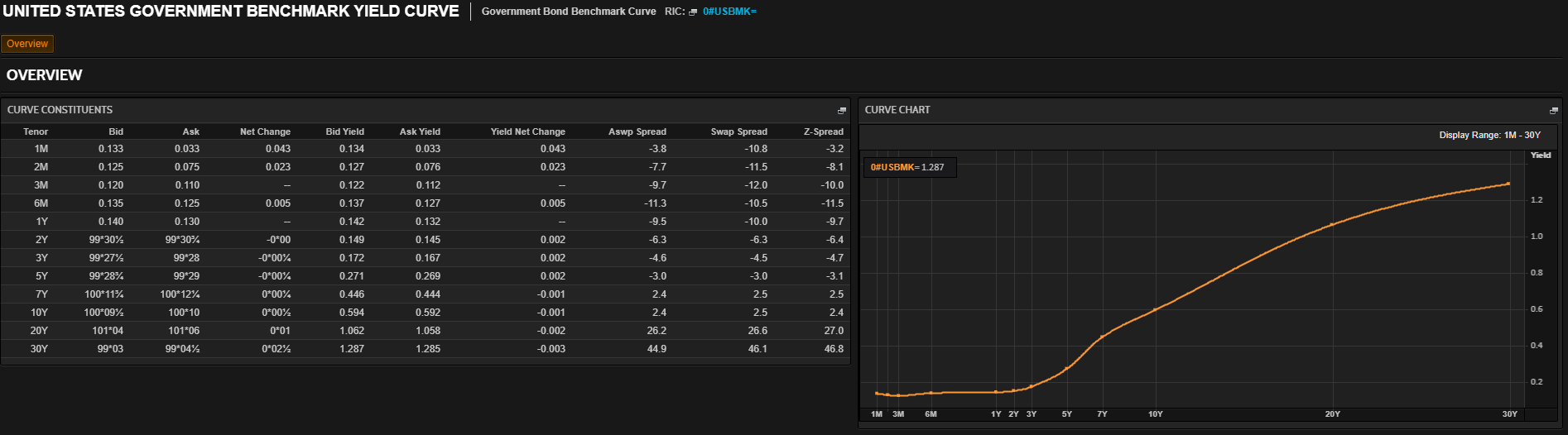
NPVs of different bonds are not comparable. That is because they account for bonds maturing at different times. Instead, YTMs of different bonds are comparable because they are annualised, therefore they account for different maturities. It is thus preferable to only speak of changes in sovereign bond NPVs in terms of the change in their YTMs; then we can compare them to each other, e.g.: in a Yield Curve (that can be seen here with Refinitiv credentials):
since no Coupons are paid for T-Bills as aformentioned (i.e.: COMTB=0), mOMTB=112<1 and FVOMTB,t= 1000 U.S.D.; all US bonds have a FV of 1000 U.S.D.. Let us use the YTMOMTB for the 13rd of July 2020 (2020-07-13) quoted on Datastream under TRUS1MT: 0.112 U.S.D.. It is quoted in U.S.D. because it was normalised for every U.S.D..
# We need to gather our data. Since Refinitiv's DataStream Web Services (DSWS) allows for access to the most accurate and wholesome end-of-day (E.O.D.) economic database (DB), naturally it is more than appropriate. We can access DSWS via the Python library "DatastreamDSWS" that can be installed simply by using pip install .
import DatastreamDSWS as DSWS
## We can use our Refinitiv's Datastream Web Socket (DSWS) API keys that allows us to be identified by Refinitiv's back-end services and enables us to request (and fetch) data:
# The username is placed in a text file so that it may be used in this code without showing it itself:
DSWS_username = open("Datastream_username.txt","r")
# Same for the password:
DSWS_password = open("Datastream_password.txt","r")
ds = DSWS.Datastream(username=str(DSWS_username.read()), password=str(DSWS_password.read()))
# It is best to close the files we opened in order to make sure that we don't stop any other services/programs from accessing them if they need to:
DSWS_username.close()
DSWS_password.close()
# Now get the data we were looking for. Note that 'TRUS1MT' is in percent, so we divide by 100 to get a ratio.
TRUS1MT_2020_07_13 = ds.get_data(tickers='TRUS1MT', start='2020-07-13',
end='2020-07-17', fields="X", freq='D')/100
TRUS1MT_2020_07_13.loc["2020-07-13"]
Instrument Field
TRUS1MT X 0.00112
Name: 2020-07-13, dtype: float64
This gives a YTM of 0.00112 (i.e.: 0.112%). Then:
NPVOMTB,t=1000 U.S.D.1+112YTMOMTB,t=1000 U.S.D.1+1120.00112≈999.9066753769649 U.S.D.since:
1000 / (1 + (1/12) * 0.00112)
999.9066753769649
With Semi-Annual Compounding
This section is purposefully added to this article to express the fact that NPVOMTB is the same with annual and semi-annual compounding; i.e.: NPVOMTB,1,t=NPVOMTB,0.5,t. With semi-annual compounding, facf=0.5 such that:
since
1000 / (1+ (0.00112/12))
999.9066753769649
We can see now that what matters is if m<facf. This far, this has indeed been the case and facf was high; but what if it wasn't? This is what we explore next. Note that sovereign bonds with maturities higher than 6 months tend to pay coupons, and this is beyond the scope of this article; for this, read 'Refinitiv Academic Article Series: Economics and Finance 101: Computing Risk Free Rates and Excess Returns from Sovereign Coupon Paying Bonds'.
With semi-monthly compounding, facf=124 such that:
since
1000 / ((1+ (0.00112/24))**2)
999.9066731995933
As predicted, NPVOMTB,124,"2020−07−13"=NPVOMTB,0.25,"2020−07−13"≈999.9066731995933<999.9066753769649≈NPVOMTB,0.5,"2020−07−13", meaning that an investor would pay less for a Bond if (s)he compounds at a shorter interval; similarly, (s)he requires a higher Yield.
With monthly compounding, facf=112. With a Three-Month T-Bill (TMTB), we use mTMTB=14 such that:
When using the Yield To Maturity of our TMTB as of 2020-07-13, i.e.: 0.00137 since
# Now get the data we were looking for. Note that 'TRUS3MT' is in percent, so we divide by 100 to get a ratio.
TRUS3MT_2020_07_13 = ds.get_data(tickers='TRUS3MT', fields="X",
start='2020-07-13', end='2020-07-17', freq='D')/100
TRUS3MT_2020_07_13.loc["2020-07-13"]
Instrument Field
TRUS3MT X 0.00137
Name: 2020-07-13, dtype: float64
Then:
NPVTMTB,112,"2020−07−13"=1000 U.S.D.(1+1120.00137)3≈999.6575781892886since
1000 / ((1 + (1/12)*0.00137)**3)
999.6575781892886
If an investor buys a One-month T-Bill for 900 U.S.D. at the start of a 30 day month, it will mature with a Face Value of 1000 U.S.D., and the investor would have made 1000−900=100 U.S.D. in profit. Over that 30 days, that's a straight-line / arithmetic return rate of 1000−900900=0.˙1 (note that the dot on top of 1 in 0.˙1 is the standard notation of a recurring decimal) , i.e.: approximately 11.11%, since:
(1000 - 900)/900
0.1111111111111111
That - itself - is a straight-line / arithmetic daily return rate of 0.˙130=0.0˙03˙7≈0.37% since:
((1000 - 900)/900)/30
0.0037037037037037034
(S)He theoretically gets that return every day (theoretically since it doesn't realise until the bond matures, i.e.: until the end of the Bond).
But investors are in the habit of re-investing their returns to benefit from compounding. This way we are not looking at straight-line / arithmetic interests, but geometric interest. The geometric daily interest of our investor is
since:
((1 + ((1000-900)/900)))**(1/30) - 1
0.0035181915469957303
(note that the 1nth exponent of a value is its nth root; this is a concept that is imperative to comprehend to understand the coding we go through below) meaning that (s)he gets approximately 900∗0.0035=3.15 USD the first day, then (900+3.15)∗0.0035≈3.16 USD the next day, and so on.
Following the same logic, it is easy to calculate the risk-free rate (rf) on any frequency. The compounding rf of our 1-Month T-Bill for any number of periods in a year (say, daily, i.e.: d) with a yield YTMOMTB,t is such that:
It is this simple because YTMs are annualised. E.g.: for a year with 252 trading days where YTMOMTB,t=0.00091 : rf=252√1+0.00091−1≈0.0000036094755657689603≈0.0004%
(1.00091**(1/252))-1
3.6094755657689603e-06
This is the YTM implied daily risk-free rate (rf) of our bond. A similar 'weekly' - 7 day - or 'monthly' - 30 day - rate can be made by letting d be the number of weeks or months for the year in question.
Why would one use 30 days (as per our example)? Because the 1-, 2-, and 3-month rates are equivalent to the 30-, 60-, and 90-day dates respectively, reported on the Board's Commercial Paper Web page. This is as per reference (see more here and here) with that said, one ought to use the exact number of days to maturity.
Note - however - that we only looked at Zero-Coupon Bonds. If m>1, then Coupons usually have to be taken into account.
We may now code a Python function to go through this method:
Development Tools & Resources
The example code demonstrating the use case is based on the following development tools and resources:
- Refinitiv's DataStream Web Services (DSWS): Access to DataStream data. A DataStream or Refinitiv Workspace IDentification (ID) will be needed to run the code below.
- Python Environment: Tested with Python 3.7
# The ' from ... import ' structure here allows us to only import the
# module ' python_version ' from the library ' platform ':
from platform import python_version
print("This code runs on Python version " + python_version())
This code runs on Python version 3.8.2
We need to gather our data. Since Refinitiv's DataStream Web Services (DSWS) allows for access to the most accurate and wholesome end-of-day (E.O.D.) economic database (DB), naturally it is more than appropriate. We can access DSWS via the Python library "DatastreamDSWS" that can be installed simply by using pip install.
# We need to gather our data. Since Refinitiv's DataStream Web Services (DSWS) allows for access to the most accurate and wholesome end-of-day (E.O.D.) economic database (DB), naturally it is more than appropriate. We can access DSWS via the Python library "DatastreamDSWS" that can be installed simply by using pip install.
import DatastreamDSWS as DSWS
# We can use our Refinitiv's Datastream Web Socket (DSWS) API keys that allows us to be identified by Refinitiv's back-end services and enables us to request (and fetch) data:
# The username is placed in a text file so that it may be used in this code without showing it itself:
DSWS_username = open("Datastream_username.txt", "r")
# Same for the password:
DSWS_password = open("Datastream_password.txt", "r")
ds = DSWS.Datastream(username=str(DSWS_username.read()),
password=str(DSWS_password.read()))
# It is best to close the files we opened in order to make sure that we don't stop any other services/programs from accessing them if they need to:
DSWS_username.close()
DSWS_password.close()
pandas will be needed to manipulate data sets
import pandas
pandas.set_option('display.max_columns', None) # This line will ensure that all columns of our dataframes are always shown
The below are needed to plot graphs of all kinds
import plotly
import plotly.express
from plotly.graph_objs import *
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode(connected=True)
import cufflinks
cufflinks.go_offline()
# cufflinks.set_config_file(offline = True, world_readable = True)
for i,j in zip(["plotly", "cufflinks", "pandas"], [plotly, cufflinks, pandas]):
print("The " + str(i) + " library imported in this code is version: " + j.__version__)
The plotly library imported in this code is version: 4.14.3
The cufflinks library imported in this code is version: 0.17.3
The pandas library imported in this code is version: 1.2.4
Create a function to compute the risk-free rate of return for any Zero-Coupon Bond's Yield To Maturity gathered from Datastream:
remember, our formula is: rf,t=d√1+YTMOMTB,t−1
This Python function will return the Zero-Coupon Bond's YTM Implied Risk Free Interest Rate, thus its name 'ZCB_YTM_Implied_r_f':
def ZCB_YTM_Implied_r_f(ytm, d):
""" ZCB_YTM_Implied_r_f Version 3.0: This Python function returns the Zero-Coupn Bond (ZCB) Yield To Maturity (YTM)
Implied Risk Free Interest Rate, thus its name 'ZCB_YTM_Implied_r_f'
ytm (Datastream pandas dataframe): The Yield To Maturity of the Zero-Coupon Bond in question.
It requiers the DSWS library from Refinitiv.
E.g.: ytm = ds.get_data(tickers = 'TRUS1MT', fields = "X", start = '1950-01-01', freq = 'D')/100
d (int): fraction of your time period to a year.
N.B.: The 1-, 2-, and 3-month rates are equivalent to 30-, 60-, and 90-day dates respectively,
as reported on the Board's Commercial Paper Web page,
such that d = 12, 12/2 and 12/3 respectively.
E.g.: d = 252
#########
Update: From Version 1.0 to 2.0:
Variables were renames with lower case characters, staying consistant with pycodestyle.
Update: From Version 2.0 to 3.0:
Corrected mistake in definition of variable `d`.
"""
# Rename the columns of 'ytm' correctly:
instrument_name = ytm.columns[0][0]
arrays = [[instrument_name], ['YTM']]
tuples = list(zip(*arrays))
ytm.columns = pandas.MultiIndex.from_tuples(tuples,
names=['Instrument', 'Field'])
# Calculate the r_f
r_f = ((ytm + 1)**(1/d))-1
# Rename the columns of r_f correctly:
instrument_name = ytm.columns[0][0]
arrays = [[instrument_name], ['YTM_Implied_r_f']]
tuples = list(zip(*arrays))
r_f.columns = pandas.MultiIndex.from_tuples(tuples,
names=['Instrument', 'Field'])
# return a list including r_f 0th and ytm 1st.
return(r_f, ytm)
Let's test the Python function with One-Month U.S. T.Bill:
test1m = ZCB_YTM_Implied_r_f(
ytm=ds.get_data(tickers='TRUS1MT', fields="X",
start='1950-01-01', end='2020-07-22', freq='D')/100,
d=12)
test1m[0].dropna()
| Instrument | TRUS1MT |
| Field | YTM_Implied_r_f |
| Dates | |
| 31/07/2001 | 0.001183 |
| 01/08/2001 | 0.00118 |
| 02/08/2001 | 0.00118 |
| 03/08/2001 | 0.001173 |
| 06/08/2001 | 0.001173 |
| ... | ... |
| 16/07/2020 | 0.000038 |
| 17/07/2020 | 0.000037 |
| 20/07/2020 | 0.000037 |
| 21/07/2020 | 0.000032 |
| 22/07/2020 | 0.00003 |
test1m[0].dropna().loc["2019-12-31"]*100
Instrument Field
TRUS1MT YTM_Implied_r_f 0.048918
Name: 2019-12-31, dtype: float64
test1m[1].dropna()
| Instrument | TRUS1MT |
| Field | YTM |
| Dates | |
| 31/07/2001 | 0.0361 |
| 01/08/2001 | 0.036 |
| 02/08/2001 | 0.036 |
| 03/08/2001 | 0.0358 |
| 06/08/2001 | 0.0358 |
| ... | ... |
| 16/07/2020 | 0.00114 |
| 17/07/2020 | 0.00112 |
| 20/07/2020 | 0.00112 |
| 21/07/2020 | 0.00096 |
| 22/07/2020 | 0.00091 |
This method of computing risk-free returns is more academic and less practical. You can think of it as 'Dirty Pricing' in a way. With that said, the notion of a risk-free return itself is theoretical, going further, the notion of a risk-free asset such as a risk-free government bond is also theoretical; it is always possible for the guarantor of the payment of the bond's Face Value at maturity to default and not make do on its promises.
Now we may compute a theoretical risk-free daily return value based on the difference in the price of the risk-free asset from one period (say day) to the next (for every unit currency invested); note that this may result in negative rf values:
1st: As aforementioned, the 1-, 2-, and 3-month rates are equivalent to the 30-, 60-, and 90-day dates respectively, reported on the Board's Commercial Paper Web page. This is as per reference (see more and here). Figures are annualized using a 360-day year or bank interest. We are using Refinitiv's Datastream YTM in percent data.
2nd: From there, we workout below the unit return from holding a one-month Treasury Bill over the period from t-1 to t by calculating its difference in daily value where: NPVOMTB,t=FVOMTB,t1+ mOMTB YTMOMTB,t=1000 U.S.D.1+112YTMOMTB,t
since FVOMTB,t= 1000 U.S.D., we are dealing with a zero-Coupon-Bond (i.e.: COMTB=0), we are using the (conventional) semi-annual compounding accounting method (i.e.: facpf=facf=0.5) and mOMTB=112<0.5 and. For YTM data from Datastream we can go for 1-Month yields (TRUS1MT) as above, or 3-Month yields (TRUS3MT).
We may thus define, for a 1-Month T-Bill: rf,t=NPVOMTB,t−NPVOMTB,t−1NPVOMTB,t−1=1000 U.S.D.1+112YTMOMTB,t−1000 U.S.D.1+112YTMOMTB,t−11000 U.S.D.1+112YTMOMTB,t−1
This Python function will return the Zero-Coupon Bond's Value Implied Risk Free Interest Rate, thus its name 'ZCB_Value_Implied_r_f':
def ZCB_Value_Implied_r_f(ytm, maturity, face_value=1000.0):
""" ZCB_Value_Implied_r_f Python Function Version 2.0: This Python function returns the Zero-Coupon Bond's Value Implied Risk Free Interest Rate, thus its name 'ZCB_Value_Implied_r_f'
face_value (float): The payment promised by the issuer of the Zero-coupon Bond at the bond's maturity-time.
Defaulted to: face_value = 1000.0
ytm (Datastream pandas dataframe): The Yield To Maturity of the Zero-Coupon Bond in question.
It requires the DSWS library from Refinitiv.
E.g.: ytm = ds.get_data(tickers = 'TRUS1MT', fields = "X", start = '1950-01-01', freq = 'D')/100
maturity (float): The number of years until the bond matures.
This can be lower than 1, e.g.: One-Month Zero-Coupon T.Bill would have a 'maturity' value of 1/12.
E.g.: maturity = 1/12
#########
Update: From Version 1.0 to 2.0:
Variables were renames with lower case characters, staying consistant with pycodestyle.
"""
# Calculate the ytm
npv = face_value/(1 + maturity * ytm)
# Rename the columns of 'V' correctly:
instrument_name = npv.columns[0][0]
arrays = [[instrument_name], ['Net Present Value']]
tuples = list(zip(*arrays))
npv.columns = pandas.MultiIndex.from_tuples(tuples, names=['Instrument',
'Field'])
# Calculate the r_f
r_f = (npv - npv.shift(periods=1))/npv.shift(periods=1)
# Rename the columns of r_f correctly:
instrument_name = npv.columns[0][0]
arrays = [[instrument_name], ['Value_Implied_r_f']]
tuples = list(zip(*arrays))
r_f.columns = pandas.MultiIndex.from_tuples(tuples, names=['Instrument',
'Field'])
# return a list including r_f 0th and YTM 1st.
return(r_f, npv)
Let's test the Python function with One-Month U.S. T.Bill:
test2 = ZCB_Value_Implied_r_f(
face_value=1000.0,
ytm=ds.get_data(tickers='TRUS1MT',
fields="X",
start='1950-01-01',
freq='D')/100,
maturity=1/12)
test2[0].dropna()
| Instrument | TRUS1MT |
| Field | Value_Implied_r_f |
| Dates | |
| 01/08/2001 | 0.000008 |
| 02/08/2001 | 0 |
| 03/08/2001 | 0.000017 |
| 06/08/2001 | 0 |
| 07/08/2001 | 0.000008 |
| ... | ... |
| 09/06/2021 | 0.000002 |
| 10/06/2021 | 0 |
| 11/06/2021 | -2E-06 |
| 14/06/2021 | -2E-06 |
| 15/06/2021 | -4E-06 |
test2[1].dropna()
| Instrument | TRUS1MT |
| Field | Net Present Value |
| Dates | |
| 31/07/2001 | 997.0007 |
| 01/08/2001 | 997.009 |
| 02/08/2001 | 997.009 |
| 03/08/2001 | 997.0255 |
| 06/08/2001 | 997.0255 |
| ... | ... |
| 09/06/2021 | 999.9958 |
| 10/06/2021 | 999.9958 |
| 11/06/2021 | 999.9933 |
| 14/06/2021 | 999.9917 |
| 15/06/2021 | 999.9875 |
Now that we have risk-free rates, it is easy to compute the excess return of any instrument.
The excess returns (XSRt) at time t are computed from its price (Pt) and the chosen risk free rate (rft) such that:
XSRt=Pt−Pt−1Pt−1−rftNote here that: Due to the differencing necessary to calculate 'XSR', the first value is empty.
We define the (time) vector
XSR=[XSR1XSR2⋮XSRT]where t∈Z and 1≤t≥T. R is thus as defined in the cell below.
Example: The S&P500 index: With the 1-Month U.S. T.Bill:
P_SPX = ds.get_data(tickers='S&PCOMP',
fields="X",
start='1950-01-01',
freq='D')
r_f = ZCB_YTM_Implied_r_f(
ytm=ds.get_data(tickers='TRUS1MT',
fields="X",
start='1950-01-01',
freq='D')/100,
d=12)[0]
# r_f and P_SPX must have the same column names to go through some algebra between one-another.
# We thus rename the columns of r_f correctly:
arrays = [["S&PCOMP"], ['X']]
tuples = list(zip(*arrays))
r_f.columns = pandas.MultiIndex.from_tuples(
tuples,
names=['Instrument', 'Field'])
XSR_SPX = ((P_SPX - P_SPX.shift(periods=1))/P_SPX.shift(periods=1)) - r_f
# We now rename the columns of R_SPX correctly:
instrument_name = P_SPX.columns[0][0]
arrays = [[instrument_name], ['Excess Returns']]
tuples = list(zip(*arrays))
XSR_SPX.columns = pandas.MultiIndex.from_tuples(
tuples,
names=['Instrument', 'Field'])
r_f.dropna()
| Instrument | S&PCOMP |
| Field | X |
| Dates | |
| 31/07/2001 | 3.94E-04 |
| 01/08/2001 | 3.93E-04 |
| 02/08/2001 | 3.93E-04 |
| 03/08/2001 | 3.91E-04 |
| 06/08/2001 | 3.91E-04 |
| ... | ... |
| 09/06/2021 | 5.56E-07 |
| 10/06/2021 | 5.56E-07 |
| 11/06/2021 | 8.89E-07 |
| 14/06/2021 | 1.11E-06 |
| 15/06/2021 | 1.67E-06 |
XSR_SPX.dropna()
| Instrument | S&PCOMP |
| Field | Excess Returns |
| Dates | |
| 31/07/2001 | 5.18E-03 |
| 01/08/2001 | 3.49E-03 |
| 02/08/2001 | 3.57E-03 |
| 03/08/2001 | -5.63E-03 |
| 06/08/2001 | -1.18E-02 |
| ... | ... |
| 09/06/2021 | -1.82E-03 |
| 10/06/2021 | 4.65E-03 |
| 11/06/2021 | 1.95E-03 |
| 14/06/2021 | 1.81E-03 |
| 15/06/2021 | -2.01E-03 |
We can create a function that goes through this: Excess Returns being abridged to 'XSReturns'
def XSReturns(p, r_f):
""" XSReturns Python Class Version 2.0: This function returns the Excess Return of any one instrument with the price 'p' collected from Datastream and any
risk-free return computed with the function 'YTM_Implied_r_f' that collects data from Datastream.
p (pandas data-frame): The price of the Instrument in mind with 2 column name rows: one for the Instrument name and the other for the field name.
E.g.: p = ds.get_data(tickers = 'S&PCOMP', fields = "X", start = '1950-01-01', freq = 'D')
r_f (pandas data-frame): The risk-free rate of return with 2 column name rows: one for the Instrument
(the Zero Coupon Bond chosen to compute r_f from) name and the other for the field name.
E.g.: r_f = ZCB_YTM_Implied_r_f(YTM = ds.get_data(tickers = 'TRUS3MT', fields = "X", start = '1950-01-01', freq = 'D')/100,
maturity = 3/12,
D = 30 * 3)[0]
#########
Update: From Version 1.0 to 2.0:
Variables were renames with lower case characters, staying consistant with pycodestyle.
"""
# r_f and P must have the same column names to go through some algebra between one-another.
# We thus rename the columns of r_f correctly:
instrument_name = p.columns[0][0]
arrays = [[instrument_name], ['X']]
tuples = list(zip(*arrays))
r_f.columns = pandas.MultiIndex.from_tuples(tuples, names=['Instrument',
'Field'])
r = ((p - p.shift(periods=1))/p.shift(periods=1)) - r_f
# We now rename the columns of R_SPX correctly:
instrument_name = p.columns[0][0]
arrays = [[instrument_name], ['Excess Returns']]
tuples = list(zip(*arrays))
r.columns = pandas.MultiIndex.from_tuples(tuples, names=['Instrument',
'Field'])
return(r)
Let's test the Python function with One-Month U.S. T.Bill:
TEST = XSReturns(p=ds.get_data(tickers='S&PCOMP', fields="X", start='1950-01-01',
freq='D'),
r_f=ZCB_YTM_Implied_r_f(ytm=ds.get_data(tickers='TRUS3MT',
fields="X",
start='1950-01-01',
freq='D')/100,
d=12/3)[0])
TEST.dropna()
| Instrument | S&PCOMP |
| Field | Excess Returns |
| Dates | |
| 01/01/1964 | -3.83E-04 |
| 02/01/1964 | 5.08E-03 |
| 03/01/1964 | 5.42E-04 |
| 06/01/1964 | 1.87E-03 |
| 07/01/1964 | -1.21E-04 |
| ... | ... |
| 09/06/2021 | -1.83E-03 |
| 10/06/2021 | 4.65E-03 |
| 11/06/2021 | 1.95E-03 |
| 14/06/2021 | 1.81E-03 |
| 15/06/2021 | -2.01E-03 |
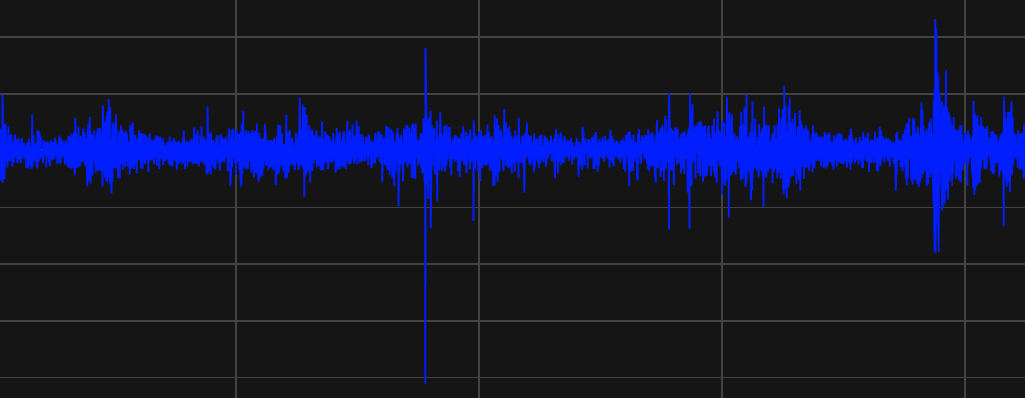
TEST.dropna().iloc[:, 0].iplot(title="S&P 500's Excess Returns",
yaxis_title="$", xaxis_title="Year",
colors="#001EFF", theme="solar")
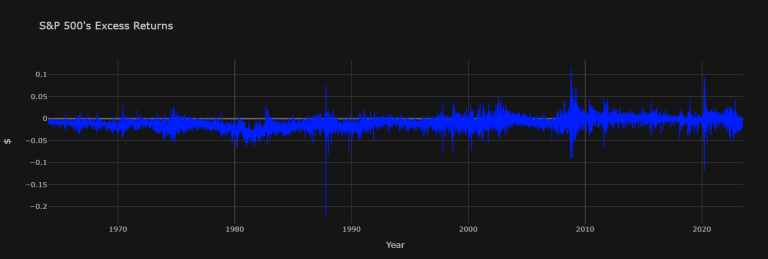
Conclusion
One may construct a Python Code to simply find the excess returns for any instrument using Datastream. Next - in Part 2 - we will investigate Coupon Paying Bonds in a realistic way.
References
Finance
Tech
You can find more detail regarding the DSWS API and related technologies for this article from the following resources:
- DSWS page on the Refinitiv Developer Community website.
- DSWS API Quick Start Guide page.
- DSWS Tutorial page.
- DSWS API Python Reference Guide.
For any questions related to this example or Eikon Data API, please use the Developers Community Q&A Forum.
