Artificial Intelligence - Feature Engineering
Overview
One of the fundamental stages of implementing a successful Artificial Intelligence solution is the feature engineering phase. It is the process of applying engineering methodologies to create new features from the raw data that can be used to train AI for inference. Feature engineering can be a computationally intensive process and requires a lot of creativity and domain knowledge. During the process business domain experts and data scientists are in close collaboration to define candidate features that model the problem space. The goal of the process is to increase AI predictive power by engineering highly informative features, well correlated with the desired AI inference space. The algorithms and actions involved range from simple decisions, such as record or feature removals to complex machine learning algorithms trying to enhance the raw dataspace by constructing never seen before data.
An important aspect of this phase is traceability across the entire pipeline. All the transformations applied during feature engineering need to be readily available to be replicated during inference as new data is flowing through the AI solution.
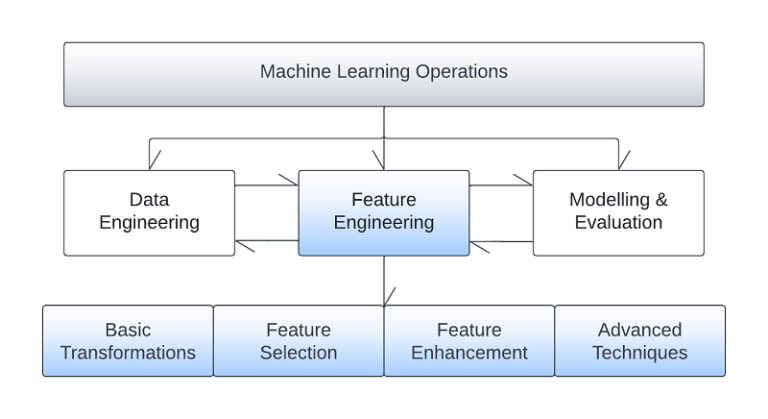
Numerous algorithms and methodologies exist that can be utilised during the phase, and we present a taxonomy of the methodologies, as well as some examples belonging to the corresponding groups.
Basic data transformations
These are some of the simpler transformations that can be applied on the dataset. The derived features can be directly created from the initial dataset using several methodologies. For example, using simple mathematical transformations, new features can be derived such as rolling averages. Combining features is also very frequent, like introducing a new column in the dataset that is the result of a computation between two existing columns. Filtering on an existing feature is another example of transformations used e.g., specific timestamps may be used to filter the entire dataset.
Feature space transformations
These are more complex techniques that aim to transform the feature space in such a way that the resulting space will be more easily explored by the AI algorithms. One of the most characteristic examples is applying kernel transformations on non-linearly separable spaces to enable linear separation. An appropriate kernel is applied and then, even a simple classifier, such as a Support Vector Classifier, can easily separate the space.
Other frequently applied transformations include encodings such as binning and quantisation and compression methods such as Principal Component Analysis.
Feature selection
Feature selection can be a very important step and is usually applied iteratively as more and more features are being engineered. The reason for this recursive nature is that as more features are introduced in the solution, they may be affecting the predictive strength of already existing ones. Calculating feature importance using quantitative or AI techniques, allows us to choose the most prominent features that can increase AI inference performance in production. The most frequently used techniques include forward or backward feature selection, feature elimination and use of univariate statistics e.g., information gain and correlation coefficients. More complex Machine Learning methodologies such as random forests can also be used.
Feature enhancement
Often, our predictive features are not in perfect condition and cannot be directly used in the AI pipeline. As an example, a typical issue that may arise with the data is that of missing values. A strategic decision needs to be taken with regards to the imputation of these missing values. Perhaps, if the missing value rows are not that many, the feature can be kept just by losing these few rows. In other situations, the missing values are many, weaken the predictive strength of the entire set, and the feature cannot be used. Other times the feature is essential given the business context and a more sophisticated strategy needs to be defined to fill in the missing values. Another example of data noise is outliers. Outlier detection is a complex process, and many techniques can be used, from simple statistical ones to more sophisticated full AI pipelines, to handle outliers.
Advanced feature engineering techniques
Sometimes, the task at hand might require more complicated data manipulation. In this situation advanced feature engineering techniques, that can range from complex algorithms to separate Artificial Intelligence pipelines, may be used to enhance the initial dataset. An example of such an advanced AI methodology is the use of Generative Adversarial Networks in the case of sparse or small datasets to generate new synthetic data that follow the existing sample distribution. Other examples include class rebalancing using SMOTE techniques or the use of auto-encoders to deconstruct existing features into simpler ones that can then be used to describe the dataset.