
Common Use Case- With Emphasis on Ease of Use
Snapshotting and Streaming 2K Instrument List with Refinitiv Data Library Python

Introduction
Refinitiv Data Library for Python provides a set of ease-of-use interfaces offering coders uniform access to the breadth and depth of financial data and services available on the Refinitiv Data Platform. It has recently became available to developers in early release, and it is a successor to RDP Library for Python.
When developers are new to Refinitiv Data Library Python, the first piece of code that we look to get working usually involves a single instrument or just a few of the instruments. Once that is accomplished, next, we are looking to implement the real-world requriements, that typically require the lists of instruments.
Next, we are going to discuss, how Refintiiv Data Library for Python allows for EASE OF USE in implementing a common use case of SNAPSHOTTING (getting all fields once) or STREAMING ( getting all fields one and any consequent updates) of a list of 2000 INSTRUMENTS.
For the requirements that are larger then 2K, the partitioning approach that we are going to discuss can be extended, by partitioning or chunking those requirements into the batches of 2K (or other preferred batch size), and requesting in batches, easily configurable and tunable to the requirement at hand.
We are going to focus on the functionality that is available and ready to use at the time of this writing.
Refinitiv Data Library Python Resources at a Glance
It may be helpful to discuss right away, how to obtain RD Library Python, and to access the developer resources fro RD Lib Python:
Refinitiv Data Library for Python- Quckstart Guide
Refinitiv Data Library for Python - Concept Guide and Documentation
Requesting 2K Pricing Snapshots
- Using stream definition without updates,
- Using get_data (chunked)
This example code that is discussed in this article and is available for download (see References section at the end) is based on EX-2.02.01-Pricing-Snapshot example, that is part of Refinitiv Data Library for Python example deck
A little setup is required before we can get started.
Import Required Libraries
import os
os.environ["RD_LIB_CONFIG_PATH"] = "../../../Configuration"
import refinitiv.data as rd
from refinitiv.data.content import pricing
import pandas as pd
Read File with 2k RICs
Our RIC file is simply formatted- one RIC per line.
defaultRICs = ['IBM.N', 'GBP=', 'JPY=', 'CAD=']
def readRICFile(filename):
if filename != '':
f = open(filename, "r")
ricList = f.read().splitlines()
print('Read '+str(len(ricList))+' RICs from file '+filename)
else:
ricList = defaultRICs
return ricList
Requesting 2k Snapshots with Stream
Desktop session, RDP Platform session(if user is permissioned for streaming) and Deployed session support requesting of snapshot over stream
Different session type options are included (see comments), we can select the required session configuration, while keeping the other available session configs commented out:
#rd.open_session('platform.rdpMachine')
#rd.open_session('platform.deployed')
rd.open_session(name='desktop.workspace',config_name='../../../Configuration/refinitiv-data.config.json')
Getting stream from a platform session:
non_streaming = rd.content.pricing.Definition(
myRics,
fields=['BID', 'ASK']
).get_stream()
or, if deployed session is used, service definition may be required to correspond to the service name as it is configured on teh local RTDS:
non_streaming = rd.content.pricing.Definition(
myRics,
fields=['BID', 'ASK'],
service = 'ELEKTRON_DD'
).get_stream()
# Open the stream in non-streaming mode
non_streaming.open(with_updates=False)
# Snapshot the prices at the time of the open() call
non_streaming.get_snapshot()
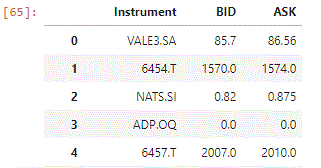
non_streaming is now available for any required access, for example:
Iterate on Instruments and Fields
for instrument in non_streaming:
print(instrument.name)
for field_name, field_value in instrument:
print(f"\t{field_name} : {field_value}")
Simplified Form Based on Stream
can be used simply by:
data = rd.get_data(myRics, fields=['BID', 'ASK'])
data
Let us go over another way
Requesting Snapshots with Get Data
Depending on permissions assigned to the user, this approach is suitable for RDP platform session, machineId or human, scopes: trapi.data.pricing.read are required
2K list submitted in a single request can result in '414 Request-URI Too Large' and so we
Chunk RIC List - Define a Helper Function
def list_to_chunks(long_list, chunk_size):
chunked_list = list()
for i in range(0, len(long_list), chunk_size):
chunked_list.append(long_list[i:i+chunk_size])
return chunked_list
and now we are ready to
Get 2K Price Snapshots as Chunked
and assemble results into a single result DataFame.
We try not to append or concat the chunk result to the overall result on every iteration, this would work as well, but this would be costly, a DataFrame is rebuilt "in-place". Instead, we append the chunk results to a list, and build the result DataFrame from the list, when completed, and only once.
dataAll = []
myRicChunks = list_to_chunks(myRics, 100)
for i in range(len(myRicChunks)):
response = rd.content.pricing.Definition(
myRicChunks[i],
fields=['BID', 'ASK']
).get_data()
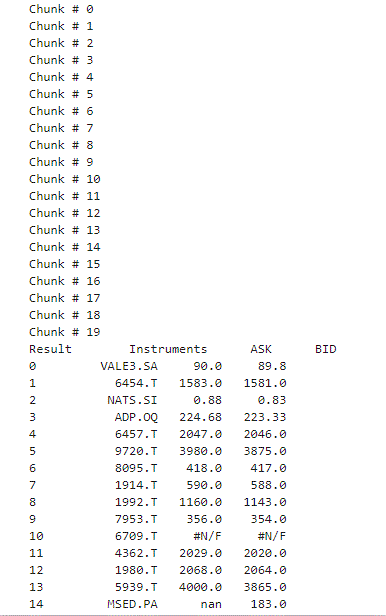
print("Chunk #", i)
dataAll.append(response.data.df)
# print(response.data.df)
dfAll = pd.concat(dataAll,ignore_index=True)
print('Displaying full result:')
display(dfAll)
We like to track the progress, and when completed we display the complete result:
next, we go over:
Requesting 2K Pricing Streaming Events
This example code is based on EX-2.02.04-Pricing-StreamingEvents example, that is part of Refinitiv Data Library for Python example deck
A little setup is required
- Import Required Libraries
- Read File with RICs
See code for these steps included at the beginning of the article and in the example on GitHub (see References section)
Open Session
Supported sesstions are:
- Desktop
- RDP platform human or machineId if permissioned for streaming pricing
- Deployed RTDS
Again, just uncomment the session configuration pointing per requirement.
i#rd.open_session()
#rd.open_session('platform.rdpMachine')
rd.open_session(name='platform.rdpMachine',config_name='../../../Configuration/refinitiv-data.config.json')
#rd.open_session(name='platform.deployed',config_name='../../../Configuration/refinitiv-data.config.json')
#rd.open_session(name='desktop.workspace',config_name='../../../Configuration/refinitiv-data.config.json')
#rd.open_session(name='platform.rdp',config_name='../../../Configuration/refinitiv-data.config.json')
Define Callbacks to Capture Incoming Events
def display_refreshed_fields(pricing_stream, instrument_name, fields):
current_time = datetime.datetime.now().time()
print(current_time, "- Refresh received for", instrument_name, ":", fields)
def display_updated_fields(pricing_stream, instrument_name, fields):
current_time = datetime.datetime.now().time()
print(current_time, "- Update received for", instrument_name, ":", fields)
...
Create a Pricing Stream and Register Event Callbacks
Note (in code, as commented out) that for Deployed session we may need to set service to use explicitly
If the service name does not match, the error may look similar to:
...'Stream': 'Closed', 'Data': 'Suspect', 'Code': 'SourceUnknown', 'Text': 'A18: Unknown service.'...
stream = rd.content.pricing.Definition(
myRics,
fields=['BID', 'ASK'],
# service = 'ELEKTRON_DD'
).get_stream()
stream.on_refresh(display_refreshed_fields)
stream.on_update(display_updated_fields)
stream.on_status(display_status)
stream.on_complete(display_complete_snapshot)
Open the Stream
To be closed the same way when we are done
stream.open()
We should be seeing refreshes and updates for the valid instruments and perhaps a few Status "{'Stream': 'Closed', 'Data': 'Suspect', 'Code': 'NotFound', 'Text': '**The record could not be found'}" for invalid instruments if they are included in the list
Next, let us look at generalizing the ease-of-use approach for larger instrument list requirements:
Request 10k List of Streaming Data
Partitioning requests into convenient bathes
Chunk RIC List - Define a Helper Function
def list_to_chunks(long_list, chunk_size):
chunked_list = list()
for i in range(0, len(long_list), chunk_size):
chunked_list.append(long_list[i:i+chunk_size])
return chunked_list
Partion the List into 2k Sub-Lists (Batches)
my2kRicChunks = list_to_chunks(my10kRics, 2000)
Create a Stream for Each Batch (Sub-List) with Callbacks
Minimize the output to be able to see the output reporting completion of each Batch - Refresh callbacks can be just "pass"-
and we store the stream handles.
def donot_display_refreshed_fields(pricing_stream, instrument_name, fields):
pass
#def donot_display_updated_fields(pricing_stream, instrument_name, fields):
# pass
streams_list = list()
for i in range(len(my2kRicChunks)):
stream = rd.content.pricing.Definition(
my2kRicChunks[i],
fields=['BID', 'ASK']
).get_stream()
stream.on_refresh(donot_display_refreshed_fields)
stream.on_update(display_updated_fields)
stream.on_status(display_status)
stream.on_complete(display_complete_snapshot)
streams_list.append(stream)
In this example we go with the simplest approach:
Open Streams Sequentially
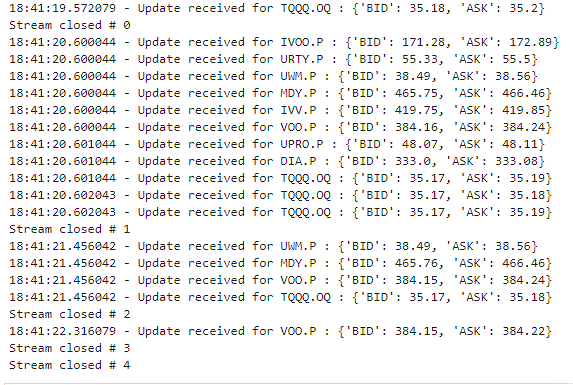
for i in range(len(streams_list)):
streams_list[i].open()
print("Stream #", i)
the diminished output allows us to track the progress:

Close Streams Sequentially (at any time)
Once all streams are closed- all the updates should cease
for i in range(len(streams_list)):
streams_list[i].close()
print("Stream closed #", i)
This wraps up our present discussion, more of the relevant information is listed in the References section
References
https://github.com/Refinitiv-API-Samples/Article.RDLibrary.Python.2KUseCase - Article Code
Refinitiv Data Library for Python- Quckstart Guide
Refinitiv Data Library for Python - Concept Guide and Documentation
Data Library for Python - Examples on GitHub
To discuss these topics further, or with other questions about Refinitiv APIs usage- get in touch with us on Refinitiv Developers Forums