
Overview
Working with Refinitiv real-time data, you probably came across a very specific type of instrument called Chains or Chain Records. If you never heard about these, well… soon or later you will probably have to deal with them. The concept of chains is quite straightforward and the process of decoding them is not that complicated. However, there are some details and subtleties that are good to know before you start working with these instruments. In this article, I will share my experience in this domain, with the hope that it will be helpful for some of you.
I structured the article in two parts. In part 1 - I explain the purpose of chains, how they are structured and how to work with them. I also give you concrete examples to illustrate these explanations. In part 2 - I present a java example application that demonstrates the concepts explained in the first part of the article. The related source code is available in Github and should give you very good indications for implementation in your own applications.
Content
About chains
The chain data structure
Chains naming
Recursive chains
How to open a chain
How to skip summary links
Chain Updates
Better performance when opening long chains
The chain example application
About chains
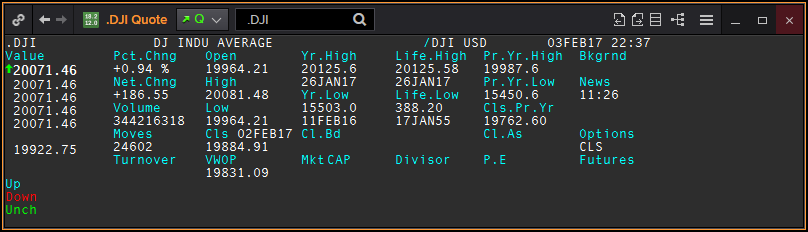
Chains are used to hold instrument names that have a common association. For example, a chain may contain the constituents of a market index like the Dow Jones or the list of strike prices on a particular option contract. It is important to note that chains contain the instrument names (a.k.a. RICs - Reuters Instrument Codes) but not the values of the instruments. If you are interested in the instruments’ values, you must explicitly request these instruments. For example, in the screenshots below, the Eikon Quote object displays both the names and the values of the Dow Jones constituents. To this aim, it first subscribed to the chain to get the names of the constituent, then it subscribed to these constituents to get their values.

The Dow Jones chain (0#.DJI) displayed in an Eikon Quote object.
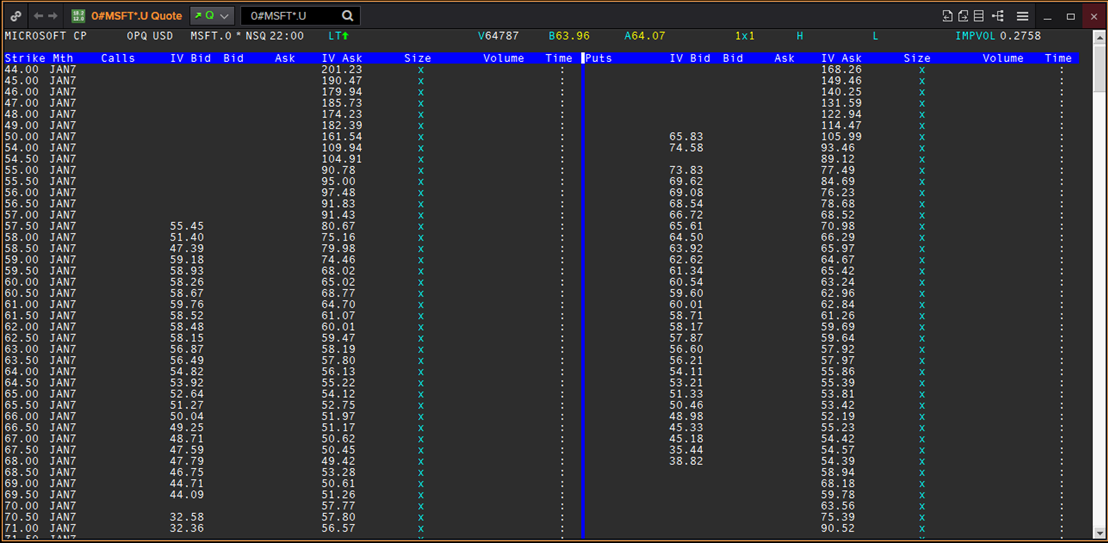
The OPRA Microsoft Equity Option Chain Contracts (0#MSFT*.U) displayed in an Eikon Quote object.
A brief history of chains
Even if chains are very specific to the MarketPrice domain, they existed way before this domain and its underlying Open Message Model (OMM) had been invented. Chains are actually a legacy of an older data distribution protocol called Marketfeed.
Notes: The MarketPrice domain is one of the Refinitiv Domain Models (RDM) built on top of the Open Message Model (OMM). The Domain Models and OMM are the data models and message models distributed by Real-Time services available within the Real-Time -- Optimized cloud-based servers or through the deployed Real-Time Distribution System (RTDS). To learn more about the different Domain Models and OMM please refer to the "RDM Usage guide" of one of the Refinitiv Real-Time SDKs.
Marketfeed was quite an innovation when Reuters introduced this protocol in its market data systems. This big technology shift leads to the phasing out of terminal-oriented standards (e.g. ANSI X3.64) and their escape sequences that mixed the data and the visual presentation of this data. This separation opened up a new world of possibilities by facilitating data acquisition, interpretation, and treatment for financial applications and algorithms.
This new Marketfeed protocol was not perfect though: Marketfeed introduced the concept of Records to hold the information related to financial instruments (One record for each instrument. Each record identified by a unique RIC). These records were made of fields. Each field had a name (e.g. BID, ASK, CLOSE…) and held a value related to the instrument. As different financial asset classes may contain different information, a record template with a predefined list of fields was defined for every asset class distributed by this protocol. One limitation of Marketfeed was that these templates were statically defined. They were able to evolve of course, but not dynamically, not on the fly. If it was perfectly fine for representing financial instruments, it became a problem for representing instruments lists of different sizes. For example, the FTSE100 British index is made of 100 constituents, the CAC40 French index is made of 40 constituents and the Dow Jones is made of 30. How do you represent all these variations with a predefined template of fields?
The technical solution Reuters found at that time was to define a special type of record that was able to contain a fixed number of RICs and that was able to be linked with other records of the same type. Thanks to this new record structure it was possible to create linked lists of groups of RICs. This dynamic data structure brought the flexibility that the Marketfeed protocol lacked. It was called Chain of records or more simply Chain.
The chain data structure
The diagram below represents the structure of a chain that contains the names of the 30 Dow Jones index constituents. The chain itself is represented by the green boxes. The blue boxes represent some of the Dow Jones constituents referenced by the chain:
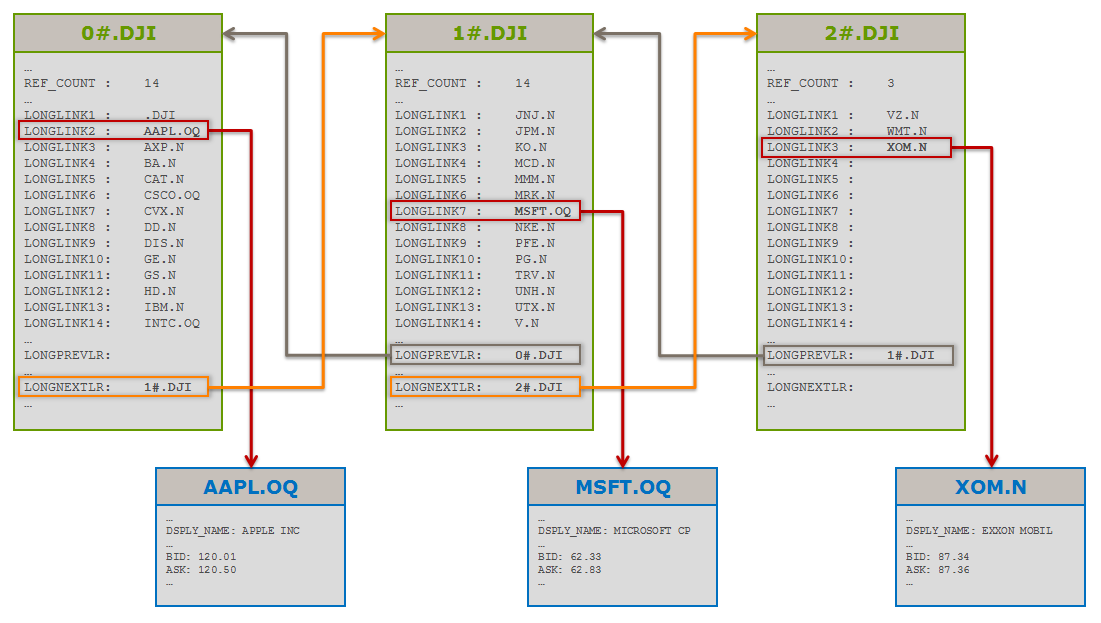
Let us have a closer look at this structure. In this particular example, the chain is composed of 3 instruments (the 3 green boxes) called Chain Records. These Chain Records, are linked together and constitute the complete chain. Chain Records are made of a specific type of MarketPrice instrument specially designed for building chains.
Chain records
A Chain Record is a MarketPrice instrument that represents a piece of a chain. Each Chain Record contains the names of up to 14 chain elements. A complete chain spans over one or several Chain Records that are linked together thanks to dedicated fields. These fields enable users and applications to navigate through the chain.
In our Dow Jones example above we see that:
- The chain is made of 3 Chain Records named 0#.DJI, 1#.DJI and 2#.DJI.
- These instruments are linked together via their LONGPREVLR and LONGNEXTLR fields.
Note: The LONGPREVLR field of 0#.DJI is empty, indicating it’s the first Chain Record of the chain. The LONGNEXTLR of the 2#.DJI is also empty, indicating it is the last Chain Record.
- The chain links to 31 elements (RICs). The first element (.DJI) is the RIC of the Dow Jones index. The other 30 elements are the RICs of the constituents of the Dow Jones.
Notes: As the 14 LONGLINKs of the first two Chain Records are used, their REF_COUNT fields are set to 14. As the last Chain Record only holds 3 elements, its REF_COUNT field is set to 3 meaning that only the first three LONGLINKS fields are used.
Chain elements
Chains only contain the names of their elements, not their values. If the application is interested in the element’s values, it must subscribe to these elements separately. In our Dow Jones example, if you’re interested in the values of the index, you must send a subscription request for .DJI. If you are interested in the values of one of its constituents – let’s say Apple – you must send a subscription request for AAPL.OQ. In the diagram above 3 of the Dow Jones constituents (Apple, Microsoft and ExxonMobil) and their values are represented by the blue boxes.
Chain record templates
There are 3 types of record template that Chain Records may use. These templates provide the same functionalities but use different fields to hold equivalent values. Because of the fields they use, templates support different RIC sizes. This is documented in the table below:
| Template #80 (Supports 10 chars in link fields) |
Template #85 (Supports 17 chars in link fields) |
Template #32766 (Supports 32 chars in link fields) |
|---|---|---|
| RDNDISPLAY | RDNDISPLAY | RDNDISPLAY |
| REF_COUNT | REF_COUNT | REF_COUNT |
| RECORD_TYPE | RECORD_TYPE | RECORD_TYPE |
| PREF_DISP | PREF_DISP | PREF_DISP |
| LINK_1 | LONGLINK1 | BR_LINK1 |
| LINK_2 | LONGLINK2 | BR_LINK2 |
| LINK_3 | LONGLINK3 | BR_LINK3 |
| LINK_4 | LONGLINK4 | BR_LINK4 |
| LINK_5 | LONGLINK5 | BR_LINK5 |
| LINK_6 | LONGLINK6 | BR_LINK6 |
| LINK_7 | LONGLINK7 | BR_LINK7 |
| LINK_8 | LONGLINK8 | BR_LINK8 |
| LINK_9 | LONGLINK9 | BR_LINK9 |
| LINK_10 | LONGLINK10 | BR_LINK10 |
| LINK_11 | LONGLINK11 | BR_LINK11 |
| LINK_12 | LONGLINK12 | BR_LINK12 |
| LINK_13 | LONGLINK13 | BR_LINK13 |
| LINK_14 | LONGLINK14 | BR_LINK14 |
| PREV_LR | LONGPREVLR | BR_PREVLR |
| NEXT_LR | LONGNEXTLR | BR_NEXTLR |
| PREF_LINK | PREF_LINK | |
| PREV_DISP | PREV_DISP |
In these templates you will mainly use the following fields:
- Links: These fields (e.g. LINK_1, LONGLINK4, BR_LINK5) represent the links to the elements of the chain. Each link field contains the name (RIC) of a chain element. The REF_COUNT field described below specifies how many link fields should be processed. If a link field is empty, it still counts as a valid chain element. The idea is that it may represent a placeholder or an intentional gap in a display. While most of the links in a chain point to similar financial instruments (e.g. equities, bonds...), many chains include one or more summary links at the beginning of the chain. For example, the first two links of the British FTSE 100 Index (FTSE 0#) are.FTSE and .AD.FTSE. These two instruments are not FTSE constituents but contain information about the index itself. Chain Records do not include any indication of which links contain summary RICs. Chain subscribers must determine this information on the fly. Please refer to the How to skip summary links section below for more details.
- Ref count: The REF_COUNT field specifies how many elements are listed in the Chain Record. The REF_COUNT field is in all of the chain templates. It is an integer that can take any value from 0 to 14. The value in REF_COUNT takes priority over the contents of link fields. For example, if REF_COUNT is 10, only links 1 through 10 should be processed. Any values that happen to be in links 11 through 14 should be ignored.
Note: Generally chain publishers use all 14 link fields before continuing to the next Chain Record. It is however not required and some chains may only use 10 links per Chain Record for example. Consequently, when REF_COUNT is less than 14, it does not signify the end of the chain. Only an empty Next field can tell you that.
- Next: Chain Records are sequenced using their Next fields (e.g. NEXT_LR, LONGNEXTLR, or BR_NEXTLR). Each Next field identifies the RIC for the next Chain Record. An empty Next field indicates the end of the chain.
- Prev: Prev fields (e.g. PREV_LR, LONGPREVLR, or BR_PREVLR) have the same role as Next fields but for stepping through a chain in reverse order. An empty Prev field indicates the beginning of the chain.
- Other fields: The other fields are used to describe the type of data the chain contains (RECORD_TYPE) and for display purposes (RDNDISPLAY, PREF_DISP, PREV_DISP, and PREF_LINK). Some of them can be used to identify the number of summary links in the chain. You’ll find more on this topic in the How to skip summary links section below. If you want to learn more about the RECORD_TYPE field I recommend you read this great article: FID 259.
These 3 Chain Record templates were created over time as there was a need for chains that support longer RICs. All of these templates were historically used within Refinitiv Servers and Desktop Applications. They are still available for backward compatibility. Except for very specific use cases, it is recommended that your application supports the 3 Chain Record templates. For example, if you intend to build an application that is able to work with any chain available on the real-time platform, it's recommended it supports the 3 templates. On the other hand, if you know that your application will only work with a limited set of well-identified chains, then you can reasonably limit your implementation to the templates used by these chains.
Chains naming
Classical chains
Classical chains are named after the RIC of their first Chain Record. For example, the Dow Jones chain is called 0#.DJI because its first Chain Record is named 0#.DJI.
Generally, the name of the first Chain Record is of the format 0#<RIC root>. Meaning this is a chain about RIC root. Then, the subsequent Chain Records are named 1#<RIC root>, 2#<RIC root>, etc. However, no assumptions should be made about the structure of the chain, neither for the number of Chain Records nor for their names or their sequence order. Therefore, you should always refer to the Next fields for determining the next Chain Records and the size of the chain.
Tiles
Tile is a term used for statistical chains that update frequently. Tiles work the same as classical chains and use the same naming. The only difference is in the name of the first Chain Record that typically omits 0#. So for example, the tile for the Active Volume leaders of NYSE is called .AV.O and is composed of two Chain Records named .AV.O and 1#.AV.O.
Recursive chains
The Dow Jones index chain I described above was quite easy to handle. With 3 Chain Records and only 31 elements, it was perfect for a first example. But as you can imagine, chains can be much longer and also more complex than that. A good example is the 0#REUTERS chain that provides all market data in a chain format. This particular chain contains RICs to other chains. It actually recursively extends over more than 10 sub-levels of chains.
Below is a screenshot of the 0#WORLD-INDICES chain that is 2 levels below its 0#REUTERS root chain:
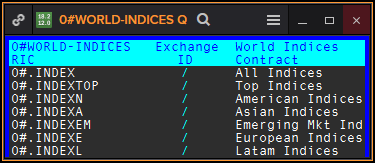
Because of the recursive nature of chains, the algorithms that deal with them may have to be recursive themselves. It depends on the use case and also on the universe of chains the application has to deal with. For example, the Eikon Quote object above doesn’t have to open chains recursively because the users are expected to click on a sub-chain RIC (like 0#.INDEX, 0#.INDEXTOP…) before the Quote actually opens it. In the same way, applications that only work with option chains do not have to be recursive neither as option chains are generally flat (no sub-chains). On the other hand, an application that would display all-cotton cash contracts would have to recursively open the 0#COTTON/CASH chain and all its sub-chains. So, recursiveness is an aspect you must consider when designing your algorithm for opening chains.
How to open a chain
How to tell if a RIC is for a chain?
Even if chains RICs often start with 0#, you cannot really tell from the instrument name if you’re dealing with a chain or not. The only reliable way to tell that is to subscribe to the instrument and verify that it contains the fields every Chain Record should contain. Theoretically, it must contain all fields listed in one of the 3 Chain Record templates described in the table above. From a more practical perspective, if your goal is only to list the chain’s elements, you just need the fields that link to the elements and those you need to navigate the chain. Depending on the type of chain, at the very minimum Chain Records must have one of these 3 sets of fields:
- REF_COUNT, NEXT_LR, PREV_LR and LINK_1 to LINK_14
- REF_COUNT, LONGNEXTLR, LONGPREVLR and LONGLINK1 to LONGLINK14
- REF_COUNT, BR_NEXTLR, BR_PREVLR and BR_LINK1 to BR_LINK14
As these 3 sets all have REF_COUNT, you can even tell that if an instrument doesn’t have a REF_COUNT field then it’s not a valid chain.
General algorithm to open a chain
Opening a chain is quite simple and usually done sequentially as described by this pseudo-code:
CurrentChainRecord = First chain record of the chain
do
Open the CurrentChainRecord
Get the names of the elements referenced by the valid Link fields.
CurrentChainRecord = Record referenced by the Next field
while CurrentChainRecord is not empty
Note: Remember that a link is considered valid only if its ID is less or equal to the reference counter. For example, if the ref counter is 4 then link5 to link14 are not considered valid even if they contain a value. See the Ref count explanations for more details.
What about the Prev link?
You may have noticed that the algorithm above doesn’t use the Prev link (PREV_LR, LONGPREVLR, or BR_PREVLR fields). In our case, it’s not needed because we browse the chain from the first element to the last. However, if for any reason you do not start with the first element of a chain, you may want to use the prev link to find the beginning of the chain.
When you open a new chain, you can also use this field to check that you’re starting from the beginning of the chain and raise an error or a warning if that's not the case.
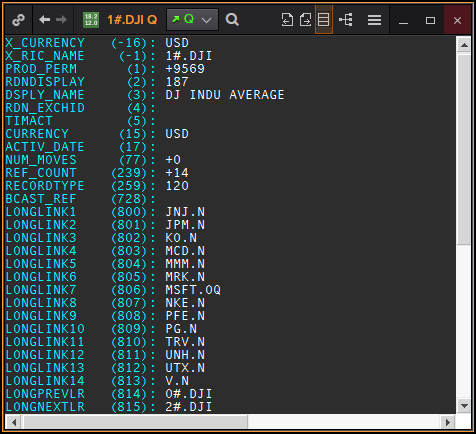
Below is a screenshot of the Eikon Quote object with the Display All Fields mode activated. In this mode the Eikon Quote object allows you to click on Prev links (LONGPREVLR in the below example) to move up the chain.
How to skip summary links
In the Dow Jones chain example, you may have noticed that the chain contains 31 elements while the Dow Jones index only has 30 constituents. If you have a closer look at the first Chain Record (0#.DJI) you’ll see that the first link (LONGLINK1) references an instrument that is not a Dow Jones constituent but the Dow Jones index itself (.DJI)
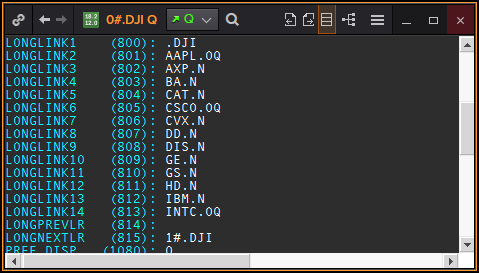
The first element of the Dow Jones chain (0#.DJI).
The Dow Jones index instrument (.DJI).
This link is called a summary link and points to an instrument that contains different information about the Dow Jones index.
On the one hand, it is desirable to have the .DJI instrument in the chain because it provides contextual information that is valuable to display beside the chain constituents. As an example, the first row of the Eikon Quote object below gives the current index value as well as the high and the low of the day.

On the other hand, if your goal is just to retrieve the 30 constituents of the Dow Jones then you do not need this information and this summary link should just be discarded. The problem is that the number of summary links differs from one chain to another. For example, the Dow Jones (0#.DJI) has 1 summary link, the British FTSE 100 (0#.FTSE) has 2 while the Italian FTSE 100 (0#.FTMIB) has 6. So, how do you know how many links you must skip?
The answer lies in the way Refinitiv applications display chains and other MarketPrice instruments. Each MarketPrice instrument has a special field that contains the ID of a display template. This template defines how each field of the instrument must be displayed (location, size, color…). For chains, it also includes knowledge of which links are summary links.
Your application probably doesn’t have access to the Refinitiv desktop display templates and you probably do not want to decode them. But, put in another way, you can say that all chains that use the same display template also have the same number of summary links. As these summary links are always the first elements of chains, your application could determine the number of these links and skip them based on the display template ID used by the chain. Unfortunately, there’s no reference table that tells you how many links you must skip for each display template. But you can easily find this information yourself by opening some of the typical chains your application works with. Then, you can then configure it based on the information you collected.
The other tricky part is to determine the display template used by your chain. Indeed, display template IDs are not contained in a single field but in one of the following three fields: RDNDISPLAY, PREV_DISP, or PREF_DISP. In addition to this, several of these fields may be in your chain and contain data. So, you must use them in priority order, as defined by this pseudo-code:
if PREF_DISP is valid then
use PREF_DISP
else if PREV_DISP is valid then
use PREV_DISP
else
use RDNDISPLAY
endif
Note: With this algorithm, a field is considered valid if:
- It exists.
- It contains a value different from "@@@", " " and "0".
Chain Updates
When you open a chain, it generally looks quite static. Don’t get this wrong: if you open the Dow Jones chain (0#.DJI) with an Eikon Quote you’ll see a lot of blinking. But this is not due to changes in the constituents list but to changes in the values of these constituents (the trade price of Apple for example). If you focus your attention on the Chain Records only, you will probably not observe any updates. Indeed, it doesn’t happen often that a company is introduced in the Dow Jones or removed from it.
Because of this "almost static" nature of chains, you may be tempted either to open chains in a non-streaming mode or to close them just after you received the complete list of elements. That may be ok for use cases where you only use the chain for a short while. For example, if you need a snapshot of the Dow Jones constituents’ values. However, if you need to keep the chain elements streaming for a long period of time, it’s probably wise to keep the Chain Records streaming as well. Doing that, you will potentially receive updates when the list of elements changes. These changes can be broken down into two categories:
- Changes limited to a single Chain Record: These changes may be caused by the addition, the removal, the swap of elements, or even by the resize of the chain. They are quite easy to handle because they only impact a single Chain Record. Thanks to this, the modifications are received via a single update, even if they involve several elements. This guarantees the atomicity of the change and thus the integrity of the chain at any time.
- Changes that impact several Chain Records: These changes may have the same causes as above, but they are more difficult to manage because they impact several Chain Records. This makes a big difference because, this time the chain changes are split into several updates and thus, are not atomic anymore. This may result in a loss of the chain integrity for a short while. For example, if a RIC is moved from Chain Record #2 to Chain Record #3, the chain provider may choose to send an update to remove the RIC from #3 and another to add it to #2. As the two updates are not received and treated atomically, the RIC will disappear from the chain when the first update is received and reappear thanks to the second update. Another option for the chain provider would be to add the RIC to #2 first and then remove it from #3. But in that case, we will observe a double RIC between the two updates.
These changes may also impact the Prev and Next fields. In that case, the application may have to close some Chain Records, open new ones and rebuild the chain structure.
Because of the non-atomic nature of some chain updates, whether you’ve chosen to open a chain dynamically or statically, your application may have to face the temporary situation of a corrupted chain. However, this should not happen often and is more likely when markets are closed.
Better performance when opening long chains
The RTDS (Real-Time Distribution System) is a highly efficient platform that brings you excellent performance when consuming real-time financial data. The asynchronous and multithreaded nature of their APIs plays a role in this performance. They allow you to request a number of instruments in parallel and to get the results at high throughput and with very low latency.
When you open a chain, it’s just natural to expect the same kind of performance, especially for this kind of instrument that does not update often. Unfortunately, chains may not bring you the excellent performance you are used to. This is inherent to the chain data structure itself. Indeed, as chain elements are requested sequentially, your application must wait for the refresh of each individual Chain Record before it can request the next. For big chains, this results in a long delay between the time the first Chain Record is requested and when the last is received. As an example, on my laptop the 0#UNIVERSE.PK chain that contains almost 17500 elements takes more than a minute to open.
There is apparently no way to get out of it. However, if you really need better performance you can try the following heuristic approach that is based on parallel subscriptions and chain naming
Ideas for an optimized algorithm
As explained in the sections above, you cannot make any assumptions about the chain structure. This means that, even if you always work with the same well-known chain, let’s say the Dow Jones (0#.DJI), you should not assume that this chain is composed of 3 Chain Records named 0#.DJI, 1#.DJI and 2#.DJI. Even if it is very unlikely, the name of the 2nd and 3rd Chain Records may change one day. Even the number of elements of the chain may change. So, when you open this chain you must do it in sequence, starting from 0#.DJI and relying on the Next fields. That is is the safe way of doing it.
However, if you want to be very quick, you could open in parallel the 3 well-known Chain Records (0#.DJI, 1#.DJI, and 2#.DJI) and verify that the chain structure did not change as soon you receive the refresh messages. If for any reason it changed, you can always fall back to the previous algorithm. Because you requested the 3 Chain Records in parallel right from the beginning, this new algorithm is more effective than the sequential one. It is also more complicated because you must know in advance the names of the Chain Records and you must verify the integrity of the chain structure while you're receiving Chain Records.
Obviously, the optimization we’re discussing here will not make any real difference for a chain with 3 Chain Records. But on the other hand, the performance improvement will certainly be noticeable with a chain like 0#UNIVERSE.PK that spans over more than 1200 Chain Records.
The most annoying aspect of this optimized algorithm is that we need to know in advance the names of the Chain Records. This may be acceptable for a single chain of 3, but probably not for long chains that were our initial motivation for improved performance.
One possible option to guess Chain Records names is to rely on the chains naming conventions. By convention, Chain Records are named 0#<RIC root>, 1#<RIC root>, 2#<RIC root>… , n#<RIC root> and tiles are named <RIC root>, 1#<RIC root>, 2#<RIC root>… , n#<RIC root>. So, once we have the name of the chain (or the tile), it’s easy to guess the names of the subsequent Chain Records. The only things we don’t know are the number of these records and whether the chain structure follows the sequential naming convention or not. But we could try to request the “guessed” Chain Records, let's say by packets of 10, and see what happens. If we receive "Record Not Found" error statuses for some of them then we know that we exceeded the size of the chain, but we can build the chain with the valid elements we’ve got. If we do not receive any wrong status, then we can continue to guess 10 new elements, etc. In any case, we must verify that the chain structure complies with our guessed structure and partially fallback to the sequential algorithm when needed.
This optimized algorithm is more complicated than the general algorithm, of course, but it is the way to go for better performance.
The chain example application
In my next article Simple Chain Objects for EMA - Part 2 I present a reusable example java library, an example application, and a command-line tool that demonstrate the different concepts explained here. These applications are based on the Java edition of the Enterprise Message API. They are available in Github and should give you a very good indication and helpful implementation in your own applications.
Leave your feedback
Your feedback is warmly welcome and can certainly help me to improve. Don’t hesitate to leave a message below or "Like" this article if you liked it.
My other articles
If you liked this article, you may be interested in reading my other articles: