
Use Case One
Refinitiv Data Platform News - Middle Office Compliance Use Cases

Introduction to Use Case
How a user can pass along a large list of identifiers: CUSIP, ISIN and or SEDOLs, and retrieve a company PermID | OrgName and status as an API response or as a bulk file
Approach
There are several possible approaches, including RDP API, to implement this Refinitiv Data Platform (RDP) News use case.
As we would like to showcase an approach in Python, and as ease of use is one of our primary considerations, the selected integration approach takes advantage of Refinitiv Data Library for Python- a brand-new, light, ease-of-use RDP integration offering, currently in pre-release.
Refinitiv Data Library for Python is documented on developer portal (see References section) and is positioned as a Refinitiv-supported member ofr Refinitiv Data Libraries family, its sister libraries being Refinitiv Data Library for .NET, and Refinitiv Data Library for TypeScript that is being prepared.
We are going to use Desktop session.
The Two Examples
- Data Library - Symbol Conversion via Search
- Data Library - Endpoint using Symbology
The reason we wish to show both approaches is that RD Library Symbol Conversion requires the RDP user to have permissions to RDP Search service. Whereas RDP Library Endpoint access only requires RDP user to have permissions to the specific endpoint in use, in this case RDP Symbology endpoint.
Data Library - Symbol Conversion via Search
- Import Refinitiv Data Library
- Open RDP Session ( Workspace)
- Setup short default list with 3 IDs
- Read working list with 2k+ IDs ( SEDOLS)
- Convert the short list of symbols to PermIDs using Symbol Conversion
- Request organization's common name and status
- Convert 2K list to PermIDs using Symbol Conversion
- Chunk the required list- define a helper function
- Run chunked request and produce single result
References section links to the complete example code on GitHub. In the next discussion we are going to focus on the specifics aspects of conversion and lookup using RD Library.
Convert the Short List to PermIDs
# Symbol types:
# - symbol_conversion.RIC => RIC
# - symbol_conversion.ISIN => IssueISIN
# - symbol_conversion.CUSIP => CUSIP
# - symbol_conversion.SEDOL => SEDOL
# - symbol_conversion.TICKER_SYMBOL => TickerSymbol
# - symbol_conversion.OA_PERM_ID => IssuerOAPermID
# - symbol_conversion.LIPPER_ID => FundClassLipperID
response = symbol_conversion.Definition(
symbols=defaultIDs,
from_symbol_type=symbol_conversion.SymbolTypes.SEDOL,
to_symbol_types=[
symbol_conversion.SymbolTypes.RIC,
symbol_conversion.SymbolTypes.OA_PERM_ID
],
).get_data()
response.data.df
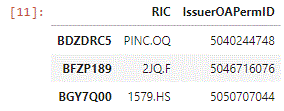
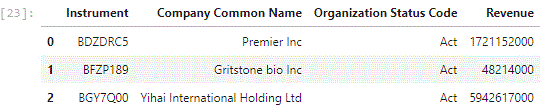
Request Company Common Name and Organization Status
Very quick and easy, adding in Revenue or any other available and required field as well.
rd.get_data(
universe=defaultIDs,
fields=['TR.CommonName','TR.OrganizationStatusCode','TR.Revenue']
)
resulting in:
Convert 2K List
If the requirement is to convert a much larger list, we may need to chunk it but 2K converts conveniently, in one request
response = symbol_conversion.Definition(
symbols=myIDs,
from_symbol_type=symbol_conversion.SymbolTypes.SEDOL,
to_symbol_types=[
symbol_conversion.SymbolTypes.RIC,
symbol_conversion.SymbolTypes.OA_PERM_ID
],
).get_data()
response.data.df
Chunking Long List- Define a Helper Function
This is a good point of time to introduce chunking. The helper function can be used whenever it is to our advantage to partition the request into smaller pieces.
The output is a convenient list of chunks of our requested size of chunk
def list_to_chunks(long_list, chunk_size):
chunked_list = list()
for i in range(0, len(long_list), chunk_size):
chunked_list.append(long_list[i:i+chunk_size])
return chunked_list
Request CommonName and OrganizationStatusCode- Submit 2K List
dfResp = rd.get_data(
universe=myIDs,
fields=['TR.CommonName','TR.OrganizationStatusCode','TR.Revenue']
)
dfResp
Request CommonName and OrganizationStatusCode - Loop Permid Chunks
For larger lists, the request may need to be partitioned into chunks of size N (default is 1000), as requesting the full list of a larger size may result in an error. We append results into a list of results and once all results are received, restructure into a single dataframe in one shot, rather then concatenating to the dataframe and re-allocating and copying detaframe.
N = 1000
permids =response.data.df['IssuerOAPermID'].astype(str).values.tolist()
myPermidChunks = list_to_chunks(permids, N)
dataAll = []
dfAll = pd.DataFrame()
for i in range(len(myPermidChunks)):
print('Iteration #',i)
dfResp = rd.get_data(
universe=myPermidChunks[i],
fields=['TR.CommonName','TR.OrganizationStatusCode','TR.Revenue']
)
dataAll.append(dfResp)
# print(dfResp)
dfAll = pd.concat(dataAll,ignore_index=True)
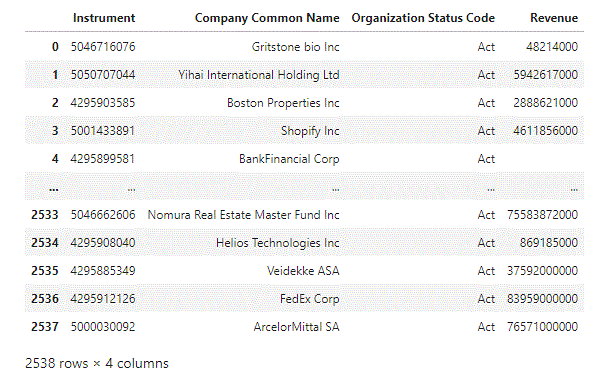
print('Displaying full result:')
display(dfAll)
results:
Let us next briefly review the same use case implementation using
Data Library - Endpoint Using Symbology
- Import Refinitiv Data Library
- Define a helper function listToChunks
- Open RDP Session ( Workspace)
- Setup short default list with 3 IDs
- Read working list with 2k+ IDs ( SEDOLS)
- Define Symbology Lookup Request Body Skeleton
- Request lookup of the short list of symbols to PermIDs using Endpoint
- Requests Lookup for Longer List of IDs using Endpoint (chunk)
- Request organization's common name and status of the short list
- Request organization's common name and status of the short list (chunk)
References section links to the complete example code on GitHub. In the next discussion we are going to focus on the specifics aspects of conversion and lookup uisng RD Library.
Define Request Body Skeleton
reqBodyPERMID = { # Specify body parameters
"from": [
{
"identifierTypes": [
"SEDOL"
],
"values": [
]
}
],
"to": [
{
"objectTypes": ["anyinstrument"],
"identifierTypes": ["PermID"]
}
],
"type": "auto"
}
defaultIDs = ['BDZDRC5','BFZP189','BGY7Q00']
reqBodyPERMID['from'][0]['values'] = defaultIDs
request_definition = rd.delivery.endpoint_request.Definition(
method = rd.delivery.endpoint_request.RequestMethod.POST,
url = 'https://api.refinitiv.com/discovery/symbology/v1/lookup',
body_parameters = reqBodyPERMID
)
response = request_definition.get_data()
response.data.raw
df = pd.json_normalize(response.data.raw, record_path =['data'])
df
Resulting in:

Requests Lookup for Longer List of IDs
In chunks and display the single result
dataAll = []
dfCompleteResult = pd.DataFrame()
for i in range(len(myIDChunks)):
reqBodyPERMID['from'][0]['values'] = myIDChunks[i]
request_definition = rd.delivery.endpoint_request.Definition(
method = rd.delivery.endpoint_request.RequestMethod.POST,
url = 'https://api.refinitiv.com/discovery/symbology/v1/lookup',
body_parameters = reqBodyPERMID
)
response = request_definition.get_data()
response.data.raw
df = pd.json_normalize(response.data.raw, record_path =['data'])
print("Requested chunk #", i)
# print(df)
dataAll.append(df)
dfCompleteResult = pd.concat(dataAll,ignore_index=True)
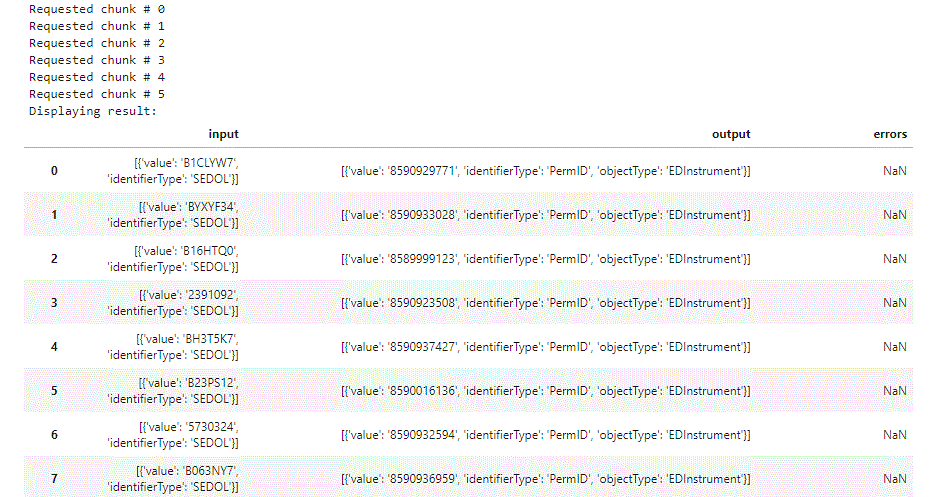
print('Displaying result:')
display(dfCompleteResult)
our result looks like:
Extract PermIds
serAll = dfCompleteResult['output'].str.get(0)
permids = []
serAll
for val in serAll:
if not pd.isna(val):
permids.append(val.get('value'))
print(permids)
Request CommonName and OrganizationStatusCode - Loop Permid Chunks
The request is partitioned into chunks of size N (default is 1000), as the full list of a larger size may result in an error
N = 1000
myPermidChunks = list_to_chunks(permids, N)
dataAll = []
dfAll = pd.DataFrame()
for i in range(len(myPermidChunks)):
print('Iteration #',i)
dfResp = rd.get_data(
universe=myPermidChunks[i],
fields=['TR.CommonName','TR.OrganizationStatusCode','TR.Revenue']
)
dataAll.append(dfResp)
#print(resp)
dfAll = pd.concat(dataAll,ignore_index=True)
print('Displaying full result:')
display(dfAll)
The results being the same Dataframe of the full required results list as we have reviewed before, we would like to conclude this brief discussion of the use case with helpful
References
- The complete source code for the use case is available on GitHub:
Refinitiv-API-Samples/Example.RDP.Python.RDPNewsMiddleOfficeComplianceUseCases (github.com)
- Quickstart Python example is available on Refinitiv developers portal:
- Refinitiv developers forums - RDP section: