
Downloading a Large Tick History Extraction Result with Postman

Introduction
The world of finance is content-driven. Data sets that we work with tend to be large, and are getting larger. Many of the use cases that we face necessitate large content sets to be retrieved from LSEG Tick History.
f the requirement is continuous or reoccurring periodically, it make sense to code and automate the solution. However if the requirement is a once-off or coming up very seldom, especially at the exploratory stage of an integration project, or during an evaluation of a content set, it's very attractive not to code an integration but use Postman to explore the content.
Postman is a collaboration platform for API development and testing. The starter edition of Postman is free, with additional functionality, collaboration-centric, available and part of purchased editions. In very simple terms, Postman allows to send fully functional, custom HTTP request requests, examine the complete detail of the responses and download the results, without having to code. The accesibility and the ease of use have made Postman very popular among developers.
Planning
If the content set that we require as our result is expected to be large, we look to plan ahead. The first step is optimizing the request, we try to minimize the request to only request what we need, we may look into splitting a giant request into a few of the logical sub requests. To lean more of optimizing of the request strategy, refer to article How to Optimize Tick History file downloads for Python (and other languages)
Using the latest (non-early adopters) Postman version also helps. At the time of this writing, I work with Postman version v9.29.0
Detecting the Issue
Once we are past the planning stage and issue the request, selecting "Send and Download":
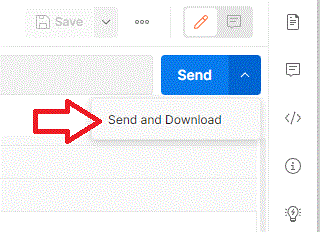
the most likely scenario is that the result downloads successfully and we are asked to point to the location to save the file to.
If this does not happen, the file may fail to download, and error can occur, or Postman may exit, silently. This last behavior can also be indicative of the result being to large.
When the result is in the process of being downloaded by Postman, the size of the complete download can be seen next to the Status:
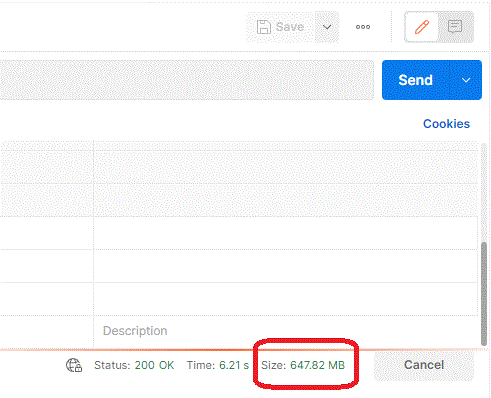
at the time of this writing, any file that is larger then 100M is likely not to be downloaded succefully with the default settings.
However, there are a couple of things that can be done to improve the situation. The first of them is configuration
Configuration
Postman Settings can be found at the top menu:
and by default are set "never to time out" and to process the response of "any size". This sounds fabulous, however, for processing of larger results, I find the following settings to be more optimal, as they allow to process files of specific size that is quite large, successfully:
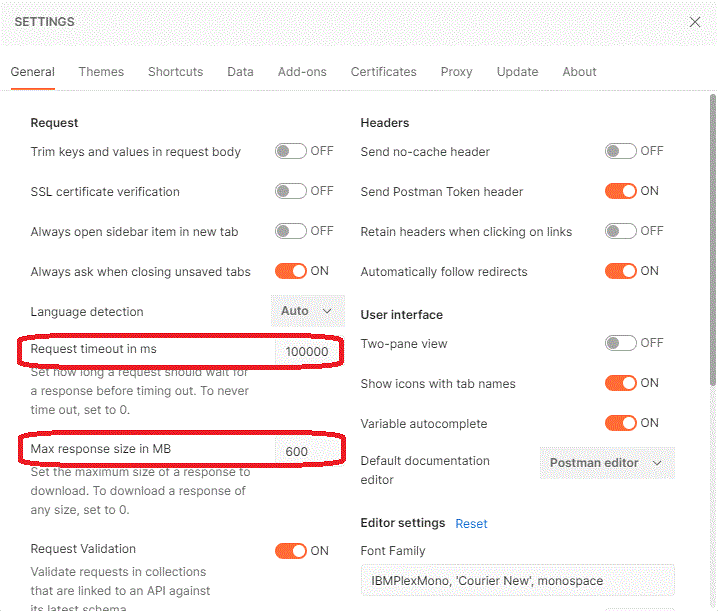
Planning and Partitioning
The result that we have used in the example is 647.82 M ( zipped). The configuration setting in place does not, from my testing, allow to download the result of this size in one piece.
However, this configuration should allow us to partition the complete result of 650M into partitions or chunks and to download. In my environment, chunks of 200- 250M work best, they consistently download without failures, quickly and with no coding or scripting required.
This size of partition of the result is not the exact science- i.e. I would expect that with a different test environment, a smaller partition would have to be used, or a larger will go through successfully.
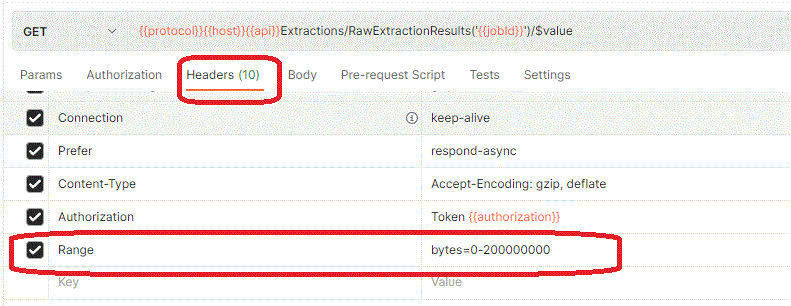
Let us look at how we use Range header on the request to enable us to partition the result:
once the file has downloaded, Postman asks where and how to save the result, and as this result is ultimately a portion of a large zipped result, I save it with extension ".gz"
next, we select to Send and Download on:

saving the result partition into the same location as the first partition was saved as response2.txt.gz.
The third and last partition will be a little large, to cover the complete required size of the total result of 650M, and it does not have to be precise in bytes, for simplicity of the Range definition, notice that Postman allows us to go larger:

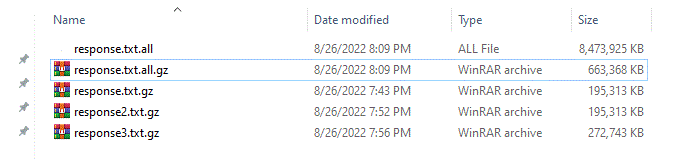
we save the last partition as response3.txt.gz. Now we should see the three partitions of the large result in the same directory:

the important note is where we have to be precise. It is in the Range definitions. Our Range definitions have to cover the total size of the result in bytes, without gaps or overlaps ( the "overhang" at the ned does not matter).:
- 0-200000000
- 200000001-400000000
- 400000001-700000000
This will allow us to restore the total result next.
Restore the Total Result
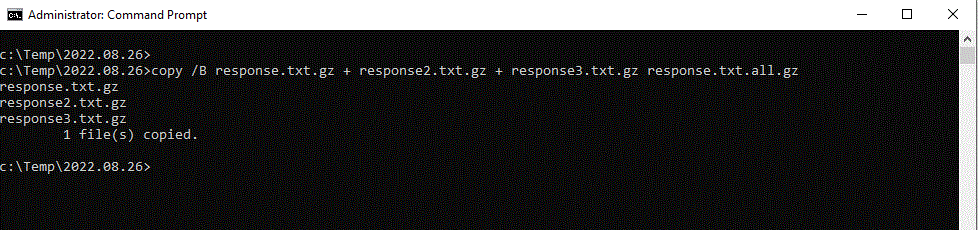
I am running on windows, so I can utilize DOS COPY to concatenate the binary files. Running from DOS command shell:
copy /B response.txt.gz + response2.txt.gz + response3.txt.gz response.txt.all.gz
resulting in file response.txt.all.gz that we should be able to successfully unzip and restore the total large extracted result:
this result is now ready to be used as required.
Afterword
I hope that you have found this brief discussion useful. To let us know your thoughts, and with suggestions for the next developer articles- visit us @ LSEG Developers Forums
References
https://www.postman.com/downloads/