
A lot of company valuation speculation has come about since the COrona-VIrus-Disease-2019 (COVID-19 or COVID for short) started to impact the stock market (estimated on the 20th of February 2020, 2020-02-20). Many investors tried to estimate the impact of the outbreak on businesses and trade accordingly as fast as possible. In this haste, it is possible that they miss-priced the effect of COVID on certain stocks.
This article lays out a framework to investigate whether the Announcement of Financial Statements after COVID (id est (i.e.): after 2020-02-20) impacted the price of stocks in any specific industry sector. It will proceed simply by producing a graph of the movement in average daily close prices for each industry - averaged from the time each company produced a Post COVID Announcement (i.e.: after they first produced a Financial Statement after 2020-02-20).
From there, one may stipulate that a profitable investment strategy could consist in going long in stocks of companies (i) that did not release an announcement since COVID yet (ii) within a sector that the framework below suggests will probably increase in price following from such an announcement.
Pre-Requisites
Required Python Packages: Refinitiv Eikon Python API, Numpy, Pandas, and Matplotlib.
The Python built in modules datetime and dateutil are also required.
Supplementary
pickle: If one wishes to copy and manipulate this code, 'pickling' data along the way should aid in making sure no data is lost when / in case there are kernel issues.
Import libraries
First, we can use the library ' platform ' to show which version of Python we are using
# The ' from ... import ' structure here allows us to only import the module ' python_version ' from the library ' platform ':
from platform import python_version
print("This code runs on Python version " + python_version())
This code runs on Python version 3.7.7
We use Refinitiv's Eikon Python Application Programming Interface (API) to access financial data. We can access it via the Python library "eikon" that can be installed simply by using pip install.
import eikon as ek
# The key is placed in a text file so that it may be used in this code without showing it itself:
eikon_key = open("eikon.txt","r")
ek.set_app_key(str(eikon_key.read()))
# It is best to close the files we opened in order to make sure that we don't stop any other services/programs from accessing them if they need to:
eikon_key.close()
The following are Python-built-in modules/libraries, therefore they do not have specific version numbers.
# datetime will allow us to manipulate Western World dates
import datetime
# dateutil will allow us to manipulate dates in equations
import dateutil
numpy is needed for datasets' statistical and mathematical manipulations
import numpy
print("The numpy library imported in this code is version: " + numpy.__version__)
The numpy library imported in this code is version: 1.18.2
pandas will be needed to manipulate data sets
import pandas
# This line will ensure that all columns of our dataframes are always shown:
pandas.set_option('display.max_columns', None)
print("The pandas library imported in this code is version: " + pandas.__version__)
The pandas library imported in this code is version: 1.0.3
matplotlib is needed to plot graphs of all kinds
import matplotlib
# the use of ' as ... ' (specifically here: ' as plt ') allows us to create a shorthand for a module (here: ' matplotlib.pyplot ')
import matplotlib.pyplot as plt
print("The matplotlib library imported in this code is version: " + matplotlib.__version__)
The matplotlib library imported in this code is version: 3.2.1
# Using an implicitly registered datetime converter for a matplotlib plotting method is no longer supported by matplotlib. Current versions of pandas requires explicitly registering matplotlib converters:
pandas.plotting.register_matplotlib_converters()
def plot1ax(dataset, ylabel = "", title = "", xlabel = "Year",
datasubset = [0], # datasubset needs to be a list of the number of each column within the dtaset that needs to be labelled on the left
datarange = False, # If wanting to plot graph from and to a specific point, make datarange a list of start and end date
linescolor = False, # This needs to be a list of the color of each vector to be plotted, in order they are shown in their dataframe from left to right
figuresize = (12,4), # This can be changed to give graphs of different proportions. It is defaulted to a 12 by 4 (ratioed) graph
facecolor="0.25",# This allows the user to change the background color as needed
grid = True, # This allows us to decide whether or not to include a grid in our graphs
time_index = [], time_index_step = 48, # These two variables allow us to dictate the frequency of the ticks on the x-axis of our graph
legend = True):
# The if statement below allows for manipulation of the date range that we would like to graph:
if datarange == False:
start_date = str(dataset.iloc[:,datasubset].index[0])
end_date = str(dataset.iloc[:,datasubset].index[-1])
else:
start_date = str(datarange[0])
# The if statement below allows us to graph to the end of the dataframe if wanted, whatever date that may be:
if datarange[-1] == -1:
end_date = str(dataset.iloc[:,datasubset].index[-1])
else:
end_date = str(datarange[-1])
fig, ax1 = plt.subplots(figsize = figuresize, facecolor = facecolor)
ax1.tick_params(axis = 'both', colors = 'w')
ax1.set_facecolor(facecolor)
fig.autofmt_xdate()
plt.ylabel(ylabel, color ='w')
ax1.set_xlabel(str(xlabel), color = 'w')
if linescolor == False:
for i in datasubset: # This is to label all the lines in order to allow matplot lib to create a legend
ax1.plot(dataset.iloc[:, i].loc[start_date : end_date],
label = str(dataset.columns[i]))
else:
for i in datasubset: # This is to label all the lines in order to allow matplot lib to create a legend
ax1.plot(dataset.iloc[:, i].loc[start_date : end_date],
label = str(dataset.columns[i]),
color = linescolor)
ax1.tick_params(axis='y')
if grid == True:
ax1.grid()
else:
pass
if len(time_index) != 0:
# locs, labels = plt.xticks()
plt.xticks(numpy.arange(len(dataset.iloc[:,datasubset]), step = time_index_step), [i for i in time_index[0::time_index_step]])
else:
pass
ax1.set_title(str(title) + " \n", color='w')
if legend == True:
plt.legend()
elif legend == "underneath":
ax1.legend(loc = 'upper center', bbox_to_anchor = (0.5, -0.3), fancybox = True, shadow = True, ncol = 5)
elif legend != False:
plt.legend().get_texts()[0].set_text(legend)
plt.show()
The cell below defines a function that adds a series of daily close prices to the dataframe named 'daily_df' and plots it.
# Defining the ' daily_df ' variable before the ' Get_Daily_Close ' function
daily_df = pandas.DataFrame()
def Get_Daily_Close(instrument, # Name of the instrument in a list.
days_back, # Number of days from which to collect the data.
plot_title = False, # If ' = True ', then a graph of the data will be shown.
plot_time_index_step = 30 * 3, # This line dictates the index frequency on the graph/plot's x axis.
col = ""): # This can be changed to name the column of the merged dataframe.
# This instructs the function to use a pre-defined ' daily_df ' variable:
global daily_df
if col == "":
# If ' col ' is not defined, then the column name of the data will be replaced with its instrument abbreviated name followed by " Close Price".
col = str(instrument) + " Close Price"
else:
pass
# This allows for the function to programmatically ensure that all instruments' data are collected - regardless of potential server Timeout Errors.
worked = False
while worked != True:
try:
instrument, err = ek.get_data(instruments = instrument,
fields = [str("TR.CLOSEPRICE(SDate=-" + str(days_back) + ",EDate=0,Frq=D,CALCMETHOD=CLOSE).timestamp"),
str("TR.CLOSEPRICE(SDate=-" + str(days_back) + ",EDate=0,Frq=D,CALCMETHOD=CLOSE)")])
instrument.dropna()
worked = True
except:
# Note that this ' except ' is necessary
pass
instrument = pandas.DataFrame(list(instrument.iloc[:,2]), index = list(instrument.iloc[:,1]), columns = [col])
instrument.index = pandas.to_datetime(instrument.index, format = "%Y-%m-%d")
if plot_title != False:
plot1ax(dataset = instrument.dropna(), ylabel = "Close Price", title = str(plot_title), xlabel = "Year", # legend ="Close Price",
linescolor = "#ff9900", time_index_step = plot_time_index_step, time_index = instrument.dropna().index)
daily_df = pandas.merge(daily_df, instrument, how = "outer", left_index = True, right_index = True)
The cell below sets up a function that gets Eikon recorded Company Announcement Data through time for any index (or instrument)
def Get_Announcement_For_Index(index_instrument, periods_back, show_df = False, show_list = False):
# This allows the function to collect a list of all constituents of the index
index_issuer_rating, err = ek.get_data(index_instrument, ["TR.IssuerRating"])
index_Announcement_list = []
for i in range(len(index_issuer_rating)):
# This allows for the function to programmatically ensure that all instruments' data are collected - regardless of potential server Timeout Errors.
worked = False
while worked != True:
try: # The ' u ' in ' index_issuer_rating_u ' is for 'unique' as it will be for each unique instrument
index_Announcement_u, err = ek.get_data(index_issuer_rating.iloc[i,0],
["TR.JPINCOriginalAnnouncementDate(SDate=-" + str(periods_back) + ",EDate=0,,Period=FI0,Frq=FI)",
"TR.JPCASOriginalAnnouncementDate(SDate=-" + str(periods_back) + ",EDate=0,,Period=FI0,Frq=FI)",
"TR.JPBALOriginalAnnouncementDate(SDate=-" + str(periods_back) + ",EDate=0,,Period=FI0,Frq=FI)"])
worked = True
except:
# Note that this ' except ' is necessary
pass
index_Announcement_list.append(index_Announcement_u)
index_Instrument = []
index_Income_Announcement = []
index_Cash_Announcement = []
index_Balance_Announcement = []
for i in range(len(index_Announcement_list)):
for j in range(len(index_Announcement_list[i])):
index_Instrument.append(index_Announcement_list[i].iloc[j,0])
index_Income_Announcement.append(index_Announcement_list[i].iloc[j,1])
index_Cash_Announcement.append(index_Announcement_list[i].iloc[j,2])
index_Balance_Announcement.append(index_Announcement_list[i].iloc[j,3])
index_Announcement_df = pandas.DataFrame(columns = ["Instrument",
"Income Statement Announcement Date",
"Cash Flos Statement Announcement Date",
"Balance Sheet Announcement Date"])
index_Announcement_df.iloc[:,0] = index_Instrument
index_Announcement_df.iloc[:,1] = pandas.to_datetime(index_Income_Announcement)
index_Announcement_df.iloc[:,2] = pandas.to_datetime(index_Cash_Announcement)
index_Announcement_df.iloc[:,3] = pandas.to_datetime(index_Balance_Announcement)
if show_df == True:
display(index_Announcement_df)
else:
pass
if show_list == True:
for i in range(len(index_Announcement_list)):
display(index_Announcement_list[i])
else:
pass
return index_Announcement_df, index_Announcement_list
COVID_start_date = datetime.datetime.strptime("2020-02-20", '%Y-%m-%d').date()
days_since_COVID = (datetime.date.today() - COVID_start_date).days
index_Announcement_df, index_Announcement_list = Get_Announcement_For_Index(index_instrument = ["0#.SPX"],
periods_back = 3,
show_df = False,
show_list = False)
Now we can choose only announcements post COVID.
Announcement_COVID_date = []
for k in (1,2,3):
index_Instruments_COVID_date = []
index_Announcement_post_COVID_list = []
for i in range(len(index_Announcement_list)):
index_Instrument_COVID_date = []
for j in reversed(index_Announcement_list[i].iloc[:,1]):
try: # Note that ' if (index_Announcement_list[i].iloc[1,1] - COVID_start_date).days >= 0: ' would not work
if (datetime.datetime.strptime(index_Announcement_list[i].iloc[:,1].iloc[-1], '%Y-%m-%d').date() - COVID_start_date).days >= 0:
while len(index_Instrument_COVID_date) == 0:
if (datetime.datetime.strptime(j, '%Y-%m-%d').date() - datetime.datetime.strptime("2020-02-20", '%Y-%m-%d').date()).days >= 0:
index_Instrument_COVID_date.append(j)
else:
index_Instrument_COVID_date.append("NaT")
except:
index_Instrument_COVID_date.append("NaT")
index_Instruments_COVID_date.append(index_Instrument_COVID_date[0])
Instruments_Announcement_COVID_date = pandas.DataFrame(index_Instruments_COVID_date, index = index_Announcement_df.Instrument.unique(), columns = ["Date"])
Instruments_Announcement_COVID_date.Date = pandas.to_datetime(Instruments_Announcement_COVID_date.Date)
Announcement_COVID_date.append(Instruments_Announcement_COVID_date)
Instruments_Income_Statement_Announcement_COVID_date = Announcement_COVID_date[0]
Instruments_Income_Statement_Announcement_COVID_date.columns = ["Date of the First Income Statement Announced after COVID"]
Instruments_Cash_Flow_Statement_Announcement_COVID_date = Announcement_COVID_date[1]
Instruments_Cash_Flow_Statement_Announcement_COVID_date.columns = ["Date of the First Cash Flow Statement Announced after COVID"]
Instruments_Balance_Sheet_COVID_date = Announcement_COVID_date[2]
Instruments_Balance_Sheet_COVID_date.columns = ["Date of the First Balance Sheet Announced after COVID"]
for i in index_Announcement_df.iloc[:,0].unique():
Get_Daily_Close(i, days_back = days_since_COVID)
Some instruments might have been added to the index midway during our time period of choice. They are the ones below:
removing = [i.split()[0] + " Close Price" for i in daily_df.iloc[0,:][daily_df.iloc[0,:].isna() == True].index]
print("We will be removing " + removing + " from our dataframe")
['CARR.N Close Price', 'OTIS.N Close Price']
The cell below will remove them to make sure that they do not skew our statistics later on in the code.
# This line removes instruments that wera added midway to the index
daily_df_no_na = daily_df.drop(removing, axis = 1).dropna()
Now we can focus on stock price movements alone.
daily_df_trend = pandas.DataFrame(columns = daily_df_no_na.columns)
for i in range(len(pandas.DataFrame.transpose(daily_df_no_na))):
daily_df_trend.iloc[:,i] = daily_df_no_na.iloc[:,i] - daily_df_no_na.iloc[0,i]
The following 3 cells display plots to visualise our data this far.
datasubset_list = []
for i in range(len(daily_df_no_na.columns)):
datasubset_list.append(i)
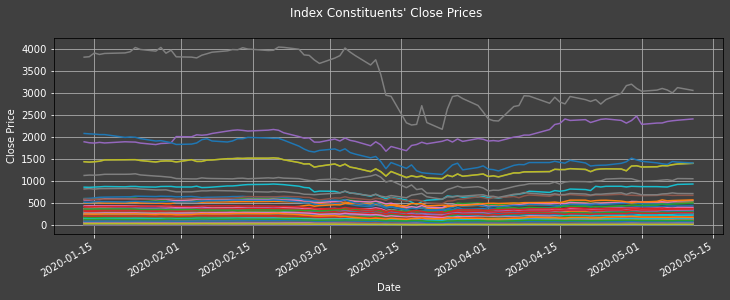
plot1ax(dataset = daily_df_no_na,
ylabel = "Close Price",
title = "Index Constituents' Close Prices",
xlabel = "Date",
legend = False,
datasubset = datasubset_list)
plot1ax(dataset = daily_df_trend, legend = False,
ylabel = "Normalised Close Price",
title = "Index Constituents' Change in Close Prices",
datasubset = datasubset_list, xlabel = "Date",)
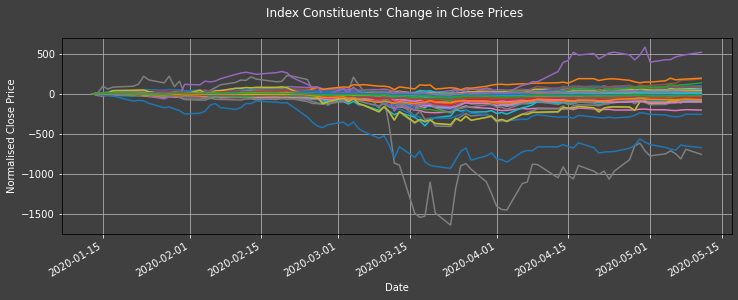
The graph above shows the change in constituent companies' close prices since COVID.
# pip install pickle-mixin
import pickle
pickle_out = open("SPX.pickle","wb")
pickl = (COVID_start_date, days_since_COVID,
index_Announcement_df, index_Announcement_list,
Announcement_COVID_date,
Instruments_Income_Statement_Announcement_COVID_date,
Instruments_Cash_Flow_Statement_Announcement_COVID_date,
Instruments_Balance_Sheet_COVID_date,
daily_df, daily_df_no_na,
daily_df_trend, datasubset_list)
pickle.dump(pickl, pickle_out)
pickle_out.close()
The cell below can be run to load these variables back into the kernel
# pickle_in = open("pickl.pickle","rb")
# COVID_start_date, days_since_COVID, index_Announcement_df, index_Announcement_list, Announcement_COVID_date, Instruments_Income_Statement_Announcement_COVID_date, Instruments_Cash_Flow_Statement_Announcement_COVID_date, Instruments_Balance_Sheet_COVID_date, daily_df, daily_df_no_na, daily_df_trend, datasubset_list = pickle.load(pickle_in)
# This is just to delimitate between the code before and after this point
daily_df2 = daily_df_no_na
The cell below formats the date-type of our data to enable us to apply them to simple algebra.
date_in_date_format = []
for k in range(len(daily_df2)):
date_in_date_format.append(daily_df2.index[k].date())
daily_df2.index = date_in_date_format
The cell below renames the columns of our dataset.
daily_df2_instruments = []
for i in daily_df2.columns:
daily_df2_instruments.append(str.split(i)[0])
Now: we collect daily prices only for dates after the first Post-COVID-Announcement of each instrument of interest
daily_df2_post_COVID_announcement = pandas.DataFrame()
for i,j in zip(daily_df2.columns, daily_df2_instruments):
daily_df2_post_COVID_announcement = pandas.merge(daily_df2_post_COVID_announcement,
daily_df2[i][daily_df2.index >= Instruments_Income_Statement_Announcement_COVID_date.loc[j].iloc[0].date()],
how = "outer", left_index = True, right_index = True) # Note that the following would not work: ' daily_df2_post_COVID_announcement[i] = daily_df2[i][daily_df2.index >= Instruments_Income_Statement_Announcement_COVID_date.loc[j].iloc[0].date()] '
Now we can focus on the trend/change in those prices
daily_df2_post_COVID_announcement_trend = pandas.DataFrame()
for i in daily_df2.columns:
try:
daily_df2_post_COVID_announcement_trend = pandas.merge(daily_df2_post_COVID_announcement_trend,
daily_df2_post_COVID_announcement.reset_index()[i].dropna().reset_index()[i] - daily_df2_post_COVID_announcement.reset_index()[i].dropna().iloc[0],
how = "outer", left_index = True, right_index = True)
except:
daily_df2_post_COVID_announcement_trend[i] = numpy.nan
And plot them
plot1ax(dataset = daily_df2_post_COVID_announcement_trend,
ylabel = "Normalised Close Price",
title = "Index Constituents' Trend In Close Prices From There First Income Statement Announcement Since COVID\n" +
"Only companies that announced an Income Statement since the start of COVID (i.e.:" + str(COVID_start_date) + ") will show",
xlabel = "Days since first Post-COVID-Announcement",
legend = False, # change to "underneath" to see list of all instruments and their respective colors as per this graph's legend.
datasubset = datasubset_list)
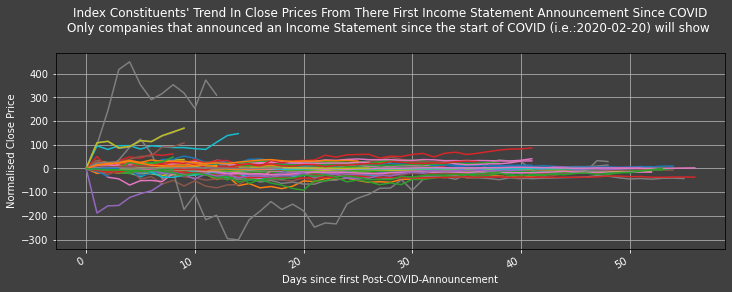
Some companies have lost and gained a great deal following from their first Post-COVID-Announcement, but most seem to have changed by less than 50 United States of america Dollars (USD).
Post COVID Announcement Price Change
The cell below simply gathers all stocks that decreased, increased or did not change in price since their first Post-COVID-Announcement in an easy to digest pandas table. Note that is they haven't had a Post-COVID-Announcement yet, they will show as unchanged.
COVID_priced_in = [[],[],[]]
for i in daily_df2_post_COVID_announcement_trend.columns:
if str(sum(daily_df2_post_COVID_announcement_trend[i].dropna())) != "nan":
if numpy.mean(daily_df2_post_COVID_announcement_trend[i].dropna()) < 0:
COVID_priced_in[0].append(str.split(i)[0])
if numpy.mean(daily_df2_post_COVID_announcement_trend[i].dropna()) == 0:
COVID_priced_in[1].append(str.split(i)[0])
if numpy.mean(daily_df2_post_COVID_announcement_trend[i].dropna()) > 0:
COVID_priced_in[2].append(str.split(i)[0])
COVID_priced_in = pandas.DataFrame(COVID_priced_in, index = ["Did not have the negative impact of COVID priced in enough",
"Had the effects of COVID priced in (or didn't have time to react to new company announcements)",
"Had a price that overcompensated the negative impact of COVID"])
COVID_priced_in
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 63 | 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 | 80 | 81 | 82 | 83 | 84 | 85 | 86 | 87 | 88 | 89 | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | 100 | 101 | 102 | 103 | 104 | 105 | 106 | 107 | 108 | 109 | 110 | 111 | 112 | 113 | 114 | 115 | 116 | 117 | 118 | 119 | 120 | 121 | 122 | 123 | 124 | 125 | 126 | 127 | 128 | 129 | 130 | 131 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 | 160 | 161 | 162 | 163 | 164 | 165 | 166 | 167 | 168 | 169 | 170 | 171 | 172 | 173 | 174 | 175 | 176 | 177 | 178 | 179 | 180 | 181 | 182 | 183 | 184 | 185 | 186 | 187 | 188 | 189 | 190 | 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 204 | 205 | 206 | 207 | 208 | 209 | 210 | 211 | 212 | 213 | 214 | 215 | 216 | 217 | 218 | 219 | 220 | 221 | 222 | 223 | 224 | 225 | 226 | 227 | 228 | 229 | 230 | 231 | 232 | 233 | 234 | 235 | 236 | 237 | 238 | 239 | 240 | 241 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Did not have the negative impact of COVID priced in enough | CHRW.OQ | PRGO.N | BA.N | MCD.N | HD.N | COG.N | AIZ.N | COST.OQ | AMD.OQ | REG.OQ | TRV.N | MOS.N | WDC.OQ | VTR.N | STX.OQ | VRSN.OQ | LB.N | LOW.N | BSX.N | MAS.N | BEN.N | RJF.N | CE.N | LLY.N | NWL.OQ | AVB.N | TPR.N | CINF.OQ | SEE.N | HON.N | NBL.OQ | EA.OQ | CB.N | MDLZ.OQ | BLL.N | JPM.N | CDW.OQ | COO.N | UAL.OQ | KHC.OQ | PNR.N | KSS.N | DPZ.N | HPQ.N | TGT.N | OXY.N | EXC.OQ | AZO.N | TEL.N | MXIM.OQ | AAL.OQ | VLO.N | LH.N | SHW.N | GD.N | SBAC.OQ | COP.N | GRMN.OQ | TXT.N | WELL.N | PLD.N | ROST.OQ | MRK.N | WEC.N | TMO.N | F.N | LYB.N | CERN.OQ | PEP.OQ | HP.N | ABMD.OQ | PH.N | NSC.N | BAX.N | GILD.OQ | JWN.N | NOC.N | PNW.N | BFb.N | DE.N | HSY.N | FLT.N | IT.N | ECL.N | BXP.N | GE.N | ED.N | WFC.N | FTV.N | PRU.N | DLTR.OQ | NEE.N | ILMN.OQ | XLNX.OQ | CMS.N | HPE.N | ALGN.OQ | SRE.N | REGN.OQ | DHR.N | CME.OQ | ADM.N | FANG.OQ | WRB.N | FLS.N | TROW.OQ | DRE.N | MLM.N | TWTR.N | L.N | QCOM.OQ | ANSS.OQ | ULTA.OQ | HRB.N | FISV.OQ | XRX.N | ANET.N | HLT.N | NFLX.OQ | AMGN.OQ | KIM.N | XRAY.OQ | URI.N | CNC.N | ANTM.N | K.N | LEG.N | PSA.N | NLSN.N | HOG.N | BK.N | MO.N | HST.N | BBY.N | LHX.N | KSU.N | FE.N | VZ.N | NEM.N | GIS.N | CMCSA.OQ | PFE.N | EIX.N | UPS.N | IP.N | MMM.N | INTU.OQ | OKE.N | ADP.OQ | EQIX.OQ | MTD.N | PEG.N | CTSH.OQ | NCLH.N | HIG.N | UHS.N | INCY.OQ | UNM.N | LRCX.OQ | PPG.N | LKQ.OQ | TJX.N | VMC.N | EW.N | ALL.N | MHK.N | CAT.N | PG.N | ZTS.N | AFL.N | CPB.N | MSI.N | ITW.N | GPS.N | ALK.N | PGR.N | DISCA.OQ | KMB.N | EL.N | SPGI.N | ADSK.OQ | WHR.N | AKAM.OQ | LUV.N | AMZN.OQ | FTI.N | BRKb.N | KR.N | BKNG.OQ | MA.N | SWK.N | DISCK.OQ | OMC.N | GLW.N | CRM.N | SBUX.OQ | TAP.N | ABT.N | JNPR.N | IRM.N | PEAK.N | FIS.N | ROK.N | HBI.N | DOW.N | PPL.N | ETN.N | CI.N | XYL.N | HAS.OQ | SO.N | VNO.N | CTL.N | DLR.N | AVY.N | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None |
| Had the effects of COVID priced in (or didn't have time to react to new company announcements) | AMCR.N | SPG.N | COTY.N | UAA.N | MYL.OQ | CAH.N | ZBH.N | AEE.N | IFF.N | MAR.OQ | ETR.N | UA.N | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None | None |
| Had a price that overcompensated the negative impact of COVID | AJG.N | CNP.N | WM.N | FOX.OQ | WY.N | HBAN.OQ | QRVO.OQ | LVS.N | AIG.N | MCO.N | DIS.N | PAYX.OQ | DHI.N | BWA.N | IVZ.N | ZBRA.OQ | SYK.N | NVR.N | SYY.N | FCX.N | EVRG.N | EXPD.OQ | PAYC.N | AIV.N | CL.N | UNH.N | ARE.N | TIF.N | ISRG.OQ | PVH.N | ADS.N | CBRE.N | WMB.N | TMUS.OQ | TXN.OQ | PFG.OQ | KEYS.N | INFO.N | RMD.N | LNT.OQ | NOV.N | CMG.N | PCAR.OQ | CHTR.OQ | PWR.N | CCL.N | PM.N | SNA.N | ESS.N | JBHT.OQ | LW.N | IR.N | WAB.N | FBHS.N | NOW.N | BR.N | EMN.N | FRT.N | DVN.N | MKC.N | IEX.N | DRI.N | MAA.N | JNJ.N | ABC.N | ORCL.N | AMP.N | ALXN.OQ | T.N | NDAQ.OQ | FFIV.OQ | SLG.N | LEN.N | CDNS.OQ | MSCI.N | IBM.N | VRTX.OQ | DXCM.OQ | AOS.N | BLK.N | HII.N | CVS.N | MSFT.OQ | HUM.N | CMA.N | GL.N | SLB.N | AWK.N | PKG.N | MMC.N | BKR.N | ALLE.N | CTVA.N | CF.N | AEP.N | FMC.N | KLAC.OQ | AME.N | NUE.N | WU.N | D.N | SJM.N | EMR.N | DVA.N | RHI.N | BDX.N | MGM.N | EFX.N | USB.N | HCA.N | NWSA.OQ | AAPL.OQ | MRO.N | APD.N | VAR.N | AXP.N | CLX.N | DOV.N | FDX.N | JKHY.OQ | O.N | PKI.N | IPG.N | PHM.N | PBCT.OQ | KO.N | WLTW.OQ | ES.N | CTAS.OQ | GPN.N | RSG.N | RF.N | PXD.N | DG.N | EQR.N | TDG.N | NKE.N | AES.N | GWW.N | GOOGL.OQ | GM.N | CCI.N | COF.N | ROP.N | CXO.N | C.N | ODFL.OQ | GS.N | MET.N | WYNN.OQ | FAST.OQ | LDOS.N | ORLY.OQ | CSX.OQ | CFG.N | NI.N | DD.N | HOLX.OQ | STT.N | JCI.N | PNC.N | ROL.N | KEY.N | NWS.OQ | MU.OQ | UNP.N | BAC.N | KMX.N | VIAC.OQ | APA.N | CHD.N | EBAY.OQ | BIIB.OQ | ALB.N | UDR.N | DGX.N | CBOE.Z | ETFC.OQ | VRSK.OQ | AMT.N | PYPL.OQ | CAG.N | TFX.N | SYF.N | WAT.N | IDXX.OQ | HES.N | EOG.N | MNST.OQ | FRC.N | BMY.N | APH.N | GPC.N | MCHP.OQ | FITB.OQ | XEL.OQ | HSIC.OQ | DFS.N | APTV.N | MPC.N | ZION.OQ | ICE.N | SWKS.OQ | EXR.N | IPGP.OQ | ADBE.OQ | WRK.N | FOXA.OQ | TSN.N | TSCO.OQ | AON.N | MS.N | GOOG.OQ | STZ.N | ABBV.N | XOM.N | HRL.N | INTC.OQ | WBA.OQ | ATO.N | HAL.N | TFC.N | ATVI.OQ | V.N | LYV.N | RE.N | FTNT.OQ | DAL.N | NTRS.OQ | CVX.N | LNC.N | ACN.N | CTXS.OQ | DISH.OQ | NRG.N | MKTX.OQ | LMT.N | PSX.N | FLIR.OQ | SCHW.N | J.N | SIVB.OQ |
ESector, err = ek.get_data(instruments = [i.split()[0] for i in daily_df2_post_COVID_announcement_trend.dropna(axis = "columns", how = "all").columns],
fields = ["TR.TRBCEconSectorCode",
"TR.TRBCBusinessSectorCode",
"TR.TRBCIndustryGroupCode",
"TR.TRBCIndustryCode",
"TR.TRBCActivityCode"])
ESector["TRBC Economic Sector"] = numpy.nan
ESector_list = [[],[],[],[],[],[],[],[],[],[]]
Sectors_list = ["Energy", "Basic Materials", "Industrials", "Consumer Cyclicals",
"Consumer Non-Cyclicals", "Financials", "Healthcare",
"Technology", "Telecommunication Services", "Utilities"]
for i in range(len(ESector["TRBC Economic Sector Code"])):
for j,k in zip(range(0, 10), Sectors_list):
if ESector.iloc[i,1] == (50 + j):
ESector.iloc[i,6] = k
ESector_list[j].append(ESector.iloc[i,0])
ESector_df = numpy.transpose(pandas.DataFrame(data = [ESector_list[i] for i in range(len(ESector_list))],
index = Sectors_list))
ESector_df_by_Sector = []
for k in Sectors_list:
ESector_df_by_Sector.append(numpy.average([numpy.average(daily_df2_post_COVID_announcement_trend[i + " Close Price"].dropna()) for i in [j for j in ESector_df[k].dropna()]]))
ESector_average = pandas.DataFrame(data = ESector_df_by_Sector,
columns = ["Average of Close Prices Post COVID Announcement"],
index = Sectors_list)
ESector_average
| Average of Close Prices Post COVID Announcement | |
|---|---|
| Energy | 0.510261 |
| Basic Materials | -0.113836 |
| Industrials | 0.557313 |
| Consumer Cyclicals | 1.606089 |
| Consumer Non-Cyclicals | 0.763417 |
| Financials | 1.065371 |
| Healthcare | 0.070465 |
| Technology | 5.372840 |
| Telecommunication Services | 1.167946 |
| Utilities | -0.540518 |
The 'ESector_average' table above shows the Close Prices Post COVID-Announcement for each company averaged per sector
The cells below now allow us to visualise this trend in a graph on an industry sector basis
Sector_Average = []
for k in ESector_average.index:
Sector_Average1 = []
for j in range(len(pandas.DataFrame([daily_df2_post_COVID_announcement_trend[i + " Close Price"].dropna() for i in ESector_df[k].dropna()]).columns)):
Sector_Average1.append(numpy.average(pandas.DataFrame([daily_df2_post_COVID_announcement_trend[i + " Close Price"].dropna() for i in ESector_df[k].dropna()]).iloc[:,j].dropna()))
Sector_Average.append(Sector_Average1)
Sector_Average = numpy.transpose(pandas.DataFrame(Sector_Average, index = ESector_average.index))
This cell below in particular allows us to collect and save our data before continuing so that we don't have to ask for data from Eikon again were we to manipulate the same content later (just in case)
pickle_out = open("SPX2.pickle","wb")
pickl = (COVID_start_date, days_since_COVID,
index_Announcement_df, index_Announcement_list,
Announcement_COVID_date,
Instruments_Income_Statement_Announcement_COVID_date,
Instruments_Cash_Flow_Statement_Announcement_COVID_date,
Instruments_Balance_Sheet_COVID_date,
daily_df, daily_df_no_na,
daily_df_trend, datasubset_list)
pickle.dump(pickl, pickle_out)
pickle_out.close()
plot1ax(dataset = Sector_Average, ylabel = "Price Movement",
title = "Index Constituents' Trend In Close Prices From There First Income Statement Announcement Since COVID Sorted By Sector\n" +
"Only companies that announced an Income Statement since the start of COVID (i.e.:" + str(COVID_start_date) + ") will show",
xlabel = "Trading Day", legend = "underneath",
datasubset = [i for i in range(len(Sector_Average.columns))])
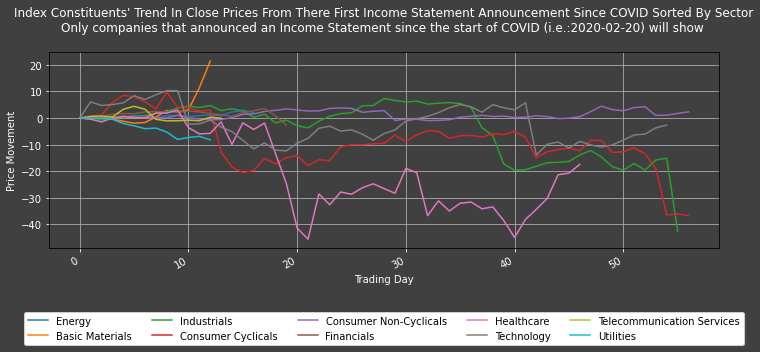
Conclusion
Using S&P 500 (i.e.: SPX) data, this last graph can provide a wholesome picture of industries in the United States of America (USA). We can see a great negative change in instruments’ daily close prices for stocks in the Consumer Cyclical, Utilities, Healthcare and Industrial markets. This is actually surprising because they are the industries that were suggested to be most hindered by COVID in the media before their financial statement announcements; investors thus ought to have priced the negative effects of the Disease on these market sectors appropriately.
The graph suggests that it may be profitable to short companies within these sectors just before they are due to release their first post-COVID Financial Statements - but naturally does not account for future changes, trade costs or other such variants external to this investigation. Companies in the Financial sector seem to have performed adequately. Reasons for movements in this sector can be complex and numerous due to their exposure to all other sectors. Tech companies seem to have had the impact of COVID priced in prior to the release of their financial statements. One may postulate the impact of COVID on their share price was actually positive as people rush to online infrastructures they support during confinement. Companies dealing with Basic Material have performed relatively well. This may be an indication that investors are losing confidence in all but sectors that offer physical goods in supply chains (rather than in consumer goods) - a retreat to fundamentals in a time of uncertainty.
BUT one must use both the ESector_average table and the last graph before coming to any conclusion. The ESector_average - though simple - can provide more depth to our analysis. Take the Healthcare sector for example: One may assume – based on the last graph alone – that this sector is performing badly when revealing information via Announcements; but the ESector_average shows a positive ‘Average of Close Prices Post COVID Announcement’. This is because only very few companies within the Healthcare sector published Announcements before May 2020, and the only ones that did performed badly, skewing the data negatively on the graph.
References
You can find more detail regarding the Eikon Data API and related technologies for this notebook from the following resources:
- Refinitiv Eikon Data API page on the Refinitiv Developer Community web site.
- Eikon Data API Quick Start Guide page.
- Eikon Data API Tutorial page.
- Python Quants Video Tutorial Series for Eikon API.
- Eikon Data API Troubleshooting article.
- Pandas API Reference.
For any question related to this example or Eikon Data API, please use the Developers Community Q&A Forum.