
Refinitiv Data Platform APIs
How To Identify And Request ESG Bulk Content - Python

Introduction
The main points to look for in the article:
- How to authenticate with RDP
- Approaches to identifying the required ESG Bulk files
- How to stream the identified files to one's desktop
Introduction to ESG Dataset and Refinitiv Data Platform Service
ESG stands for Environmental, Social and (Corporate) Governance data.
Refinitiv Data Platform (RDP) provides simple web based API access to a broad range of content, including ESG content and ESG content in bulk.
With growing popularity of socially conscious investing, Refinitiv offers one of the most comprehensive Environmental, Social and Governance (ESG) databases in the industry, covering over 80% of global market cap, across more than 450 different ESG metrics, with history going back to 2002. Customers looking to download our ESG content can do so through our bulk API service in Refinitiv Data Platform (RDP). RDP is a cloud based API that provides a single access point to all Refinitiv content.
ESG data is the first content made available in our bulk API service known as Client File Store (CFS). This capability allows our customers to download our entire history of ESG coverage. To more about how the ESG Bulk Service works in Refinitiv Data Platform, please visit:
https://developers.refinitiv.com/refinitiv-data-platform/refinitiv-data-platform-apis/docs
Within RDP family of service, ESG Bulk is part of Client File Store (CFS) - based section of service, find out more at:
https://developers.refinitiv.com/en/api-catalog/refinitiv-data-platform/refinitiv-data-platform-apis
Let us now focus on the programmatic interaction with ESG Bulk RDP service.
Python Environment
For the purpose of demonstration, we are going to use Python 3.7 and Jupiter Lab
Valid Credentials - Replace in Code or Read From File
Valid RDP credentials are required to interact with an RDP service.
USERNAME = "VALIDUSER"
PASSWORD = "VALIDPASSWORD"
CLIENT_ID = "SELFGENERATEDCLIENTID"
def readCredsFromFile(filePathName):
### Read valid credentials from file
global USERNAME, PASSWORD, CLIENT_ID
credFile = open(filePathName,"r") # one per line
#--- RDP MACHINE ID---
#--- LONG PASSWORD---
#--- GENERATED CLIENT ID---
USERNAME = credFile.readline().rstrip('\n')
PASSWORD = credFile.readline().rstrip('\n')
CLIENT_ID = credFile.readline().rstrip('\n')
credFile.close()
readCredsFromFile("..\creds\credFileHuman.txt")
# Uncomment - to make sure that creds are either set in code or read in correctly
#print("USERNAME="+str(USERNAME))
#print("PASSWORD="+str(PASSWORD))
#print("CLIENT_ID="+str(CLIENT_ID))
We include two ways to supply the valid credentials.
- One is, to replace the placeholders in code, "VALIDUSER" ... with the valid personal credential values. To enact, comment out the call to read cred from file:
#readCredsFromFile("..\creds\credFileHuman.txt")
- The other way is to store a set of valid RDP credentials in a file that is stored in path "../creds" in file "credsFileHuman.txt" and have the code retrieve the credentials from the file.
The file is expected to be in simple format one entity per line:
VALIDUSER
VALIDPASSWORD
SELFGENERATEDCLIENTID
Define Token Handling and Obtain a Valid Token
Having a valid token is a pre-requisite to requesting of any RDP content, and will be passed into the next steps. For additional information on Authorization and Tokens, refer to RDP Tutorial: Authorization - All about tokens.
The implementation steps that come next may look familiar, as with some variation they come up repeatedly, with any RDP service interaction.
TOKEN_ENDPOINT = RDP_BASE_URL + CATEGORY_URL + RDP_AUTH_VERSION + ENDPOINT_URL
def _requestNewToken(refreshToken):
if refreshToken is None:
tData = {
"username": USERNAME,
"password": PASSWORD,
"grant_type": "password",
"scope": SCOPE,
"takeExclusiveSignOnControl": "true"
};
else:
tData = {
"refresh_token": refreshToken,
"grant_type": "refresh_token",
};
# Make a REST call to get latest access token
response = requests.post(
TOKEN_ENDPOINT,
headers = {
"Accept": "application/json"
},
data = tData,
auth = (
CLIENT_ID,
CLIENT_SECRET
)
)
if response.status_code != 200:
raise Exception("Failed to get access token {0} - {1}".format(response.status_code, response.text));
# Return the new token
return json.loads(response.text);
def saveToken(tknObject):
tf = open(TOKEN_FILE, "w+");
print("Saving the new token");
# Append the expiry time to token
tknObject["expiry_tm"] = time.time() + int(tknObject["expires_in"]) - 10;
# Store it in the file
json.dump(tknObject, tf, indent=4)
def getToken():
try:
print("Reading the token from: " + TOKEN_FILE);
# Read the token from a file
tf = open(TOKEN_FILE, "r+")
tknObject = json.load(tf);
# Is access token valid
if tknObject["expiry_tm"] > time.time():
# return access token
return tknObject["access_token"];
print("Token expired, refreshing a new one...");
tf.close();
# Get a new token from refresh token
tknObject = _requestNewToken(tknObject["refresh_token"]);
except Exception as exp:
print("Caught exception: " + str(exp))
print("Getting a new token using Password Grant...");
tknObject = _requestNewToken(None);
# Persist this token for future queries
saveToken(tknObject)
# Return access token
return tknObject["access_token"];
accessToken = getToken();
print("Have token now");
print("Token is: " + accessToken)
Request Available FileSets
The purpose of ESG bulk service is obtaining ESG content in bulk. The content is available as:
- A full JSON data file containing history for all measures and all organizations.
- A delta JSON data file that contains only incremental changes to the universe since last week.
A customer can examine the available File Sets that are permissioned to them, and is expected to:
- Build the initially available ESG content set/representation with the full files
- Apply delta, changes, as they become available
- Fill the gap in ESG content, if the retrieval was not completed, and the content that was missed remains available
This step serves to verify the permissioned type of the file, for example:
- ESGRawFullScheme
- ESGScoresFull
- ESGScoresWealthFull
FILESET_ENDPOINT = RDP_BASE_URL+'/file-store'+RDP_ESG_BULK_VERSION + '/file-sets?bucket='+ RDP_ESG_BUCKET
def requestFileSets(token, withNext, skipToken, attributes):
global FILESET_ENDPOINT
print("Obtaining FileSets in ESG Bucket...")
FILESET_ENDPOINT = RDP_BASE_URL+'/file-store'+RDP_ESG_BULK_VERSION + '/file-sets?bucket='+ RDP_ESG_BUCKET
querystring = {}
payload = ""
jsonfull = ""
jsonpartial = ""
headers = {
'Content-Type': "application/json",
'Authorization': "Bearer " + token,
'cache-control': "no-cache"
}
if attributes:
FILESET_ENDPOINT = FILESET_ENDPOINT + attributes
if withNext:
FILESET_ENDPOINT = FILESET_ENDPOINT + '&skipToken=' +skipToken
print('GET '+FILESET_ENDPOINT )
response = requests.request("GET", FILESET_ENDPOINT, data=payload, headers=headers, params=querystring)
if response.status_code != 200:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers['Authorization'] = "Bearer " + accessToken
response = requests.request("GET", FILESET_ENDPOINT, data=payload, headers=headers, params=querystring)
print('Raw response=');
print(response);
if response.status_code == 200:
jsonFullResp = json.loads(response.text)
return jsonFullResp;
else:
return '';
jsonFullResp = requestFileSets(accessToken, False, '','');
Paginate Through the Available FileSets
This step allows to see what filesets are presently made available, as this can change overtime.
i = 1
while "@nextLink" in jsonFullResp:
print('<<< Iteraction: '+str(i)+' >>> More exists: '+ jsonFullResp['@nextLink'] + ', skipToken is: ' + jsonFullResp['@nextLink'][-62:]+'\n')
jsonFullResp = requestFileSets(accessToken, True, jsonFullResp['@nextLink'][-62:],'');
print(json.dumps(jsonFullResp, indent=2));
i+=1;
print('Last response without next=');
print(json.dumps(jsonFullResp, indent=2));
Retrieve FileSets of Specific File Type (Filter By Attribute)
The file types may change over time, at the time of this writing, the available FileSets are of types:
- ESG Raw Full A
- ESG Raw Full B
- ESG Raw Current A
- ESG Raw Current B
- ESG Sources
- ESG Raw Wealth Standard
- Symbology Cusip
- Symbology SEDOL
- Symbology Organization
- Symbology Instrument Quote
So if we wish to request only "Symbology Cusip" filesets, we go:
requestFileSets(accessToken, False, '','&attributes=ContentType:Symbology Cusip');
From the output we select File Id of the file or files that we are interested in downloading. for example:
...
"files": [ "48c8-c367-10b639d6-9128-0e00b40dea98" ],
...
Or if we wish to filter by Package Id (this is a recommended approach, enter and use PACKAGE_ID from the package IDs permissioned to your user id and supplied to you by your Refinitiv contact):
jsonFullResp = requestFileSets(accessToken, False, '','&packageId='+PACKAGE_ID); #+'&attributes=ContentType:ESG Sources');
The results are made available in parsed json view:
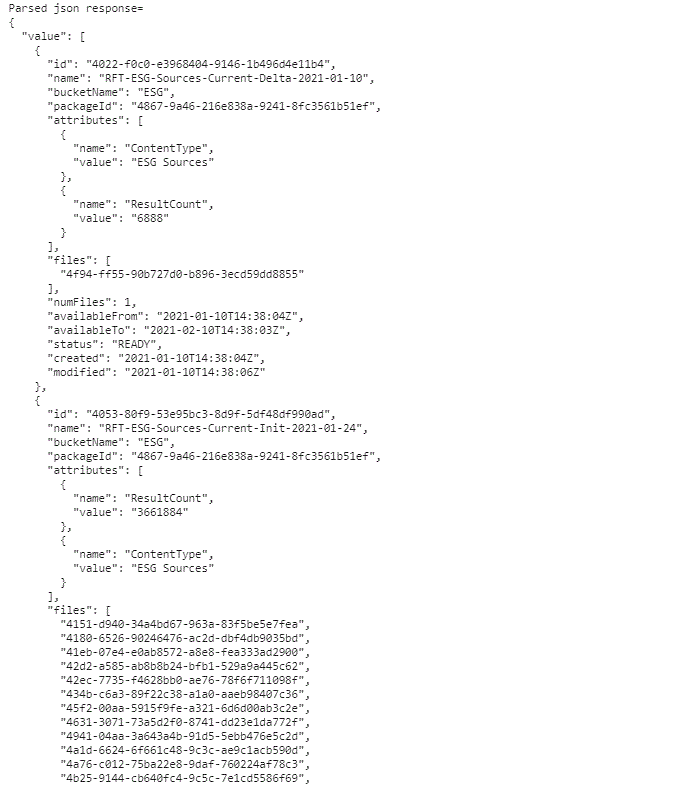
As well as tabular view by structuring into pandas dataframe:
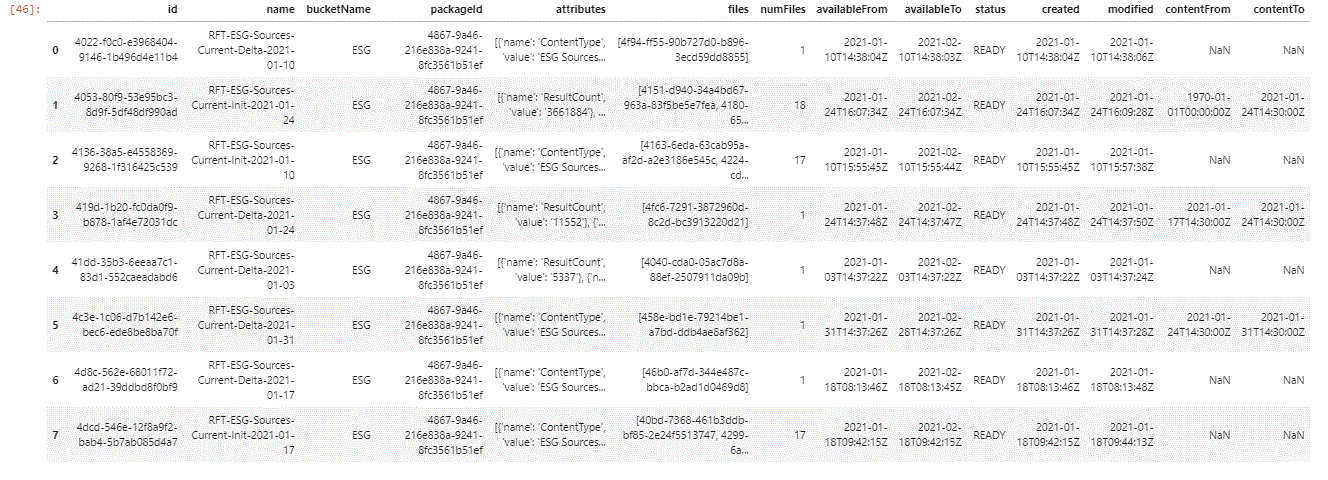
Retrieving Complete File Details of a FileSet
Once we have identified the FileSet id for the FileSet that we are interested in, we request the complete details, so we can learn the specific File ids and their corresponding File names.
FILES_ENDPOINT_START = RDP_BASE_URL+'/file-store'+RDP_ESG_BULK_VERSION + '/files?filesetId='
def requestFileDetails(token, fileSetId):
print("Obtaining File details for FileSet= "+ fileSetId + " ...")
print("(If result is Response=400, make sure that fileSetId is set with a valid value...)")
FILES_ENDPOINT = FILES_ENDPOINT_START + fileSetId
querystring = {}
payload = ""
jsonfull = ""
jsonpartial = ""
headers = {
'Content-Type': "application/json",
'Authorization': "Bearer " + token,
'cache-control': "no-cache"
}
response = requests.request("GET", FILES_ENDPOINT, data=payload, headers=headers, params=querystring)
if response.status_code != 200:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers['Authorization'] = "Bearer " + accessToken
response = requests.request("GET", FILES_ENDPOINT, data=payload, headers=headers, params=querystring)
print('Raw response=');
print(response);
if response.status_code == 200:
jsonFullResp = json.loads(response.text)
return jsonFullResp;
else:
return '';
jsonFullResp = requestFileDetails(accessToken, FILESET_ID);
There are two ways of downloading the files:
Stream File via FileId using Redirect
This is a single request approach to obtaining the required file
import shutil
FILES_STREAM_ENDPOINT_START = RDP_BASE_URL+'/file-store'+RDP_ESG_BULK_VERSION + '/files/'
# use valid values, obtained from the previous step
exampleFileId = '4edd-99af-da829f42-8ddd-07fabfcddca9'
exampleFileName = 'RFT-ESG-Sources-Full-Init-2021-01-17-part07.jsonl.gz'
def requestFileDownload(token, fileId, fileName):
FILES_STREAM_ENDPOINT = FILES_STREAM_ENDPOINT_START + fileId+ '/stream'
print("Obtaining File ... " + FILES_STREAM_ENDPOINT)
chunk_size = 1000
headers = {
'Authorization': 'Bearer ' + token,
'cache-control': "no-cache",
'Accept': '*/*'
}
response = requests.request("GET", FILES_STREAM_ENDPOINT, headers=headers, stream=True, allow_redirects=True)
# running on windows and colons are not allowed in filenames
fileName = fileName.replace(":",".")
if response.status_code != 200:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers['Authorization'] = "Bearer " + accessToken
response = requests.request("GET",FILES_STREAM_ENDPOINT, headers=headers, stream=True, allow_redirects=True)
print('Response code=' + str(response.status_code));
if response.status_code == 200:
print('Processing...')
with open(fileName, 'wb') as fd:
shutil.copyfileobj(response.raw, fd)
print('Look for gzipped file named: '+ fileName + ' in current directory')
response.connection.close()
return;
# consider below an example only
requestFileDownload(accessToken, exampleFileId, exampleFileName);
#requestFileDownload(accessToken, FILE_ID, FILE_NAME);
Please note at the end of the code snippet, how we can call either with hard-coded exampleFileId and exampleFileName or we can enter FILE_ID and FILE_NAME via variable. Use the preferred approach.
Or
We can first obtain the direct file download URL (or multiple URLs) and then download the files explicitly, from URLs:
Get File Location (Step 1 of 2)
import shutil
FILES_STREAM_ENDPOINT_START = RDP_BASE_URL+'/file-store'+RDP_ESG_BULK_VERSION + '/files/'
DIRECT_URL = ''
def requestFileLocation(token, fileId):
FILES_STREAM_ENDPOINT = FILES_STREAM_ENDPOINT_START + fileId+ '/stream?doNotRedirect=true'
print("Obtaining File ... " + FILES_STREAM_ENDPOINT)
filename = FILE_NAME
chunk_size = 1000
headers = {
'Authorization': 'Bearer ' + token,
'cache-control': "no-cache",
'Accept': '*/*'
}
response = requests.request("GET", FILES_STREAM_ENDPOINT, headers=headers, stream=False, allow_redirects=False)
if response.status_code != 200:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers['Authorization'] = "Bearer " + accessToken
response = requests.request("GET",FILES_STREAM_ENDPOINT, headers=headers, stream=False, allow_redirects=False)
print('Response code=' + str(response.status_code));
if response.status_code == 200:
jsonFullResp = json.loads(response.text)
print('Parsed json response=');
print(json.dumps(jsonFullResp, indent=2));
DIRECT_URL = jsonFullResp['url'];
print('File Direct URL is: ' +str(DIRECT_URL)+ '|||');
return jsonFullResp['url'];
else:
return 'Error response: '+ response.text
DIRECT_URL = requestFileLocation(accessToken, FILE_ID);
from urllib.parse import urlparse, parse_qs
def requestDirectFileDownload(token, directUrl, fileName):
global DIRECT_URL
print("Obtaining File from URL... " + directUrl)
#Parse out URL parameters for submission into requests
url_obj = urlparse(DIRECT_URL)
parsed_params = parse_qs(url_obj.query)
# extract the URL without query parameters
parsed_url = url_obj._replace(query=None).geturl()
response = requests.get(parsed_url, params=parsed_params,stream=True)
if response.status_code != 200:
if response.status_code == 401: # error when token expired
accessToken = getToken(); # token refresh on token expired
headers['Authorization'] = "Bearer " + accessToken
response = requests.get(parsed_url, params=query)
print('Response code=' + str(response.status_code));
filename = 'another_'+fileName
if response.status_code == 200:
print('Processing...')
with open(filename, 'wb') as fd:
shutil.copyfileobj(response.raw, fd)
print('Look for gzipped file named: '+ filename + ' in current directory')
response.connection.close()
return;
requestDirectFileDownload(accessToken, DIRECT_URL, FILE_NAME);
Let us now examine a very common use case
Select the Latest ESG FileSets (Init and Delta) as of Last Sunday per PackageId
import datetime
# determine what date last Sunday was
d = datetime.datetime.today()
#print(d)
sun_offset = (d.weekday() - 6) % 7
sunday = d - datetime.timedelta(days=sun_offset)
# format Sunday date to ESG bulk current requirements
sunday = sunday.replace(hour=0, minute=0, second=0, microsecond=0)
sunday = str(sunday).replace(' 00:00:00', 'T00:00:00Z')
print("Last Sunday was on", sunday)
PACKAGE_ID = '4867-9a46-216e838a-9241-8fc3561b51ef'
ESG_FILESET_RESP = requestFileSets(accessToken, False, '','&packageId='+PACKAGE_ID+'&availableFrom='+ sunday);
print('Parsed json response=');
print(json.dumps(ESG_FILESET_RESP, indent=2));
# now ESG_FILESET_RESP contains the requisite FileSetIds
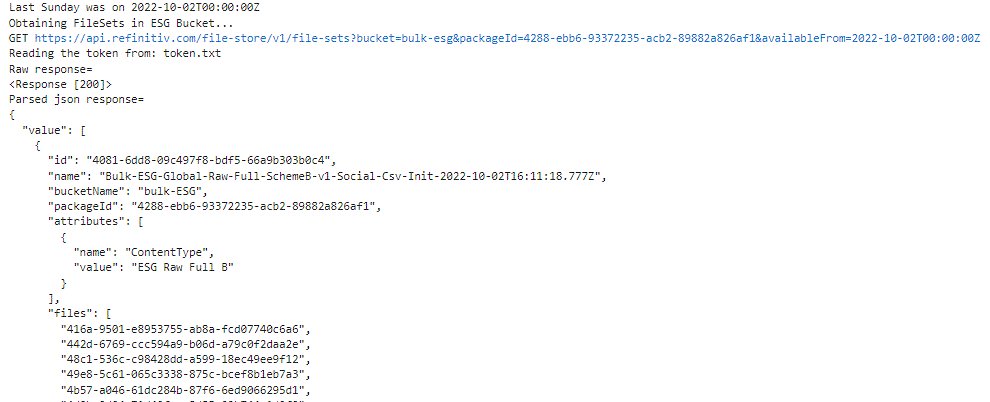
now that we have identified the FilesEts that we require, we are able to iterate over the identified files and request them for download:
Iterate over Latest ESG FileSets and Request the Latest ESG Files (Init and Delta)
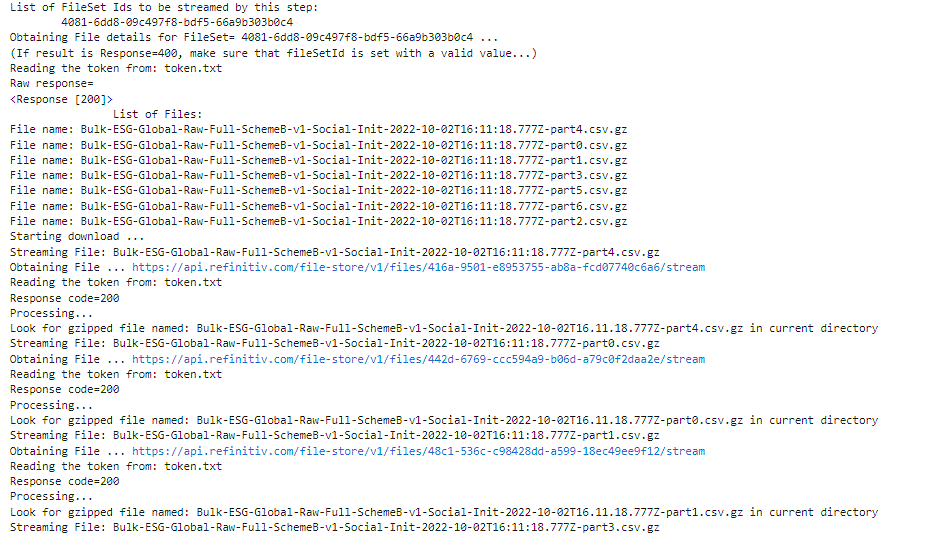
print("List of FileSet Ids to be streamed by this step:")
for item in ESG_FILESET_RESP['value']:
print ('\t'+item['id'])
# Request File Details for the FileSets of interest
jsonFullRespFile = requestFileDetails(accessToken, item['id']);
print('\t\tList of Files:')
for item2 in jsonFullRespFile['value']:
print ('File name: ' +item2['filename'])
# Request download per file Id and into fileName
print('Starting download ... ')
for item2 in jsonFullRespFile['value']:
print ('Streaming File: ' +item2['filename'])
requestFileDownload(accessToken, item2['id'],item2['filename']);
This article is brought to developers in collaboration with ESG Bulk product management team.
And next, would like to leave off with relevant ESG Bulk information:
Example.RDPAPI.Python.ESGBulkIntroduction