

Knowledge Prerequisite – Must have a basic understanding of the Enterprise Message API and be familiar with using the OmmConsumer class to consume Market Price data - as a minimum ( see tutorials EMA C++ and EMA Java).
EMA (Enterprise Message API) is designed as an ease of use API which provides one of the easiest entry points into consuming and publishing real-time data.
One way it achieves this is by defaulting behaviours. For example; when making making a data item request, EMA defaults to a MarketPrice Streaming request - as this is the most common data request type. If you want a different domain or a snapshot you need to override the default.
This default behaviour also applies to the configuration aspects of EMA. So if you don't provide a config file when establishing a Consumer connection to a server, EMA defaults to downloaded dictionary, a log level of Success, localhost for the server, port number of 14002 and so on (see config guides for more details - EMA Java and EMA C++).
When creating an OmmConsumer you have to provide an OmmConsumerConfig instance as a minimum. The default behaviour of OmmConsumer is hard coded into the OmmConsumerConfig class. You can change this default behaviour in a number of ways
- Using OmmConsumerConfig methods for some key parameters
- Using an EmaConfig.xml file
- Passing in config data via the OmmConsumerConfig::config() method - EMA C++ v1.0 onward and EMA Java 1.2.1 onward
OmmConsumerConfig Class
Deployed Credentials
When consuming data from a deployed Refinitiv Real-Time Distribution system, you will need a valid username / DACS ID. By default, EMA will use your Windows or Linux username. If, however, you need to specify an alternative ID then you will need to override the default using the following:
C++: OmmConsumerConfig & username (const EmaString &username)
Java: OmmConsumerConfig username(java.lang.String username)
Cloud Credentials
If you are connecting to one of our Cloud-based services such as Refinitiv Real-Time Optimized, then you would also use the above to specify your MachineID for the username as well set the associated password and ClientID (also known as AppKey) for example:
C++:
OmmConsumerConfig config;
config.username( "Your MachineID" );
config.password( "Your long MachineID Password" );
config.clientId( "Your AppKey" );
Java:
OmmConsumerConfig config = EmaFactory.createOmmConsumerConfig();
config.username( "Your MachineID" );
config.password( "Your long MachineID Password" );
config.clientId( "Your AppKey" );
Deployed Server
The other main parameter you will most likely need to override is the hostname for the server you are connecting to. EMA defaults this to localhost:14002 (where 14002 is the default port number on most servers for Consumer type connections).
C++: OmmConsumerConfig & host (const EmaString &host="localhost:14002")
Java: OmmConsumerConfig host(java.lang.String host)
The host() will accept a hostname or IP address for the server you wish to connect to. If the server uses the default port of 14002 (usually the case) you can omit the port:
C++:
...
OmmConsumer consumer( OmmConsumerConfig().host("10.12.234.56" ) );
...
Java:
...
consumer = EmaFactory.createOmmConsumer(EmaFactory.createOmmConsumerConfig().host("myads1:14002"));
...
While we are on the subject of servers; those of you that have used our other APIs will be familiar with the recommended practice of specifying more than one server - using the serverlist parameter rather than a single hostname. EMA also offers similar functionality with ChannelSets which we will cover later.
The OmmConsumerConfig class only exposes a few key parameters - to override the others we can use the EmaConfig.xml file (or programmatic config).
Connecting to Refinitiv Real-Time Optimized or other Cloud-based Services
Whilst the above server config instructions relate to a deployed server, you may be using one of our Cloud-based services such as Refinitiv Real-Time Optimized. For details on how to connect to these, I recommend you refer to the Session Management example 113 and the Service Discovery example 450. These are provided with the Java and C++ versions of EMA and can be found in the Training Consumer 100 Series and 400 Series example folders of each SDK.
NOTE: Whilst it is possible to specify the cloud-based Refinitiv Real-time endpoints as the host value, we do not recommend you do this in practice. It is better to use the Session Management feature and allow EMA to connect to whichever endpoint it deems appropriate at the time - which it does by querying a Service Discovery system on your behalf.
EmaConfig.xml file for Consumers
For the most part, the EmaConfig.xml configuration parameters are the same for EMA C++ and EMA Java. There a few differences - mostly around Logger output and the low-level message Trace configuration - which I will cover later.
EMA configuration data is based around the idea of Groups containing Lists; for Consumers, it is divided into the following groups:
- Consumer : High level - specifies which Channel, dictionary, Logger groups etc to use
- Channel : Connectivity related - e.g. connection type, hostname, port, buffer sizes etc
- Dictionary : Specify local or server dictionaries
- Logger : API Logging levels etc (EMA C++ only)
The easiest way to put the above into context is to look at an example of each type - starting with Consumer.
Consumer Group
<ConsumerGroup>
<DefaultConsumer value="Consumer_1"/>
<ConsumerList>
<Consumer>
<!-- Name is mandatory-->
<Name value="Consumer_1"/>
<!-- Channel is optional: defaulted to "RSSL_SOCKET+localhost+14002"-->
<!-- Channel or ChannelSet may be specified -->
<Channel value="Channel_1"/>
<!-- Dictionary is optional: defaulted to "ChannelDictionary"-->
<Dictionary value="Dictionary_1"/>
<XmlTraceToStdout value="0"/>
<XmlTraceToFile value="1"/>
<Logger value="Logger_2"/>
</Consumer>
<Consumer>
<Name value="Consumer_2"/>
<!-- ChannelSet specifies an ordered list of Channels to which OmmConsumer will attempt -->
<!-- to connect, one at a time, if the previous one fails to connect-->
<ChannelSet value="Channel_1, Channel_2"/>
<Dictionary value="Dictionary_2"/>
<XmlTraceToStdout value="0"/>
<Logger value="Logger_1"/>
</Consumer>
</ConsumerList>
</ConsumerGroup>
The ConsumerGroup contains a ConsumerList with one or more Consumer configurations in the list. Each Consumer configuration must have a name. When creating an OmmConsumerConfig instance you can chose which configuration to use by specifying the name:
C++: config = OmmConsumerConfig().consumerName( "Consumer_2" );
Java: config = EmaFactory.createOmmConsumerConfig().consumerName("Consumer_2");
If you don't specify a Consumer name in your code, then EMA will use the DefaultConsumer parameter in your EmaConfig.xml file and load that configuration. If you don't have a DefaultConsumer parameter, then it will load the first Consumer configuration in the Consumer group - which in the above example would be Consumer_1 anyway.
Channels and ChannelSets
After you have named the Consumer configuration, the next parameter specifies the Channel configuration(s) to be used by this Consumer. If you want to attempt a connection to a single server then you specify a Channel value with the name of the Channel configuration to use. If however, you want to and are able to use the recommended approach of specifying one or more failover servers, then you should use a ChannelSet.
A Channel configuration specifies the connectivity parameters to be used for connecting to a data source - I will cover in more detail later.
A ChannelSet is, as the name suggests, a set of Channels. The advantage of using ChannelSets, is that the API will automatically try each Channel in the set until a sucessfull connection is made. So, if the first source is down, it will try the 2nd without any intervention from the application. Similarly, if a working connection goes down at some later point in time, EMA will automatically try and connect to the next Channel in the set.
In the above example, EMA will try to connect to the source specified in Channel_1 and if that is down/goes down it will try Channel_2. Using ChannelSets is the recommend approach where you have more than one data source / server available in your organization.
Note that, if for some reason, you specify both a Channel and a ChannelSet in your Consumer configuration, then EMA uses the later one in the file i.e. if you specify a Channel and then a ChannelSet, it will use the ChannelSet.
Just like the Consumer configurations are grouped in the Consumer Group, the Channel configurations are grouped in the Channel Group.
Below is an example of a ChannelGroup which contains a ChannelList with two Channel configurations:
<ChannelGroup>
<ChannelList>
<Channel>
<Name value="Channel_1"/>
<ChannelType value="ChannelType::RSSL_SOCKET"/>
<!-- CompressionType is optional: defaulted to None -->
<!-- possible values: None, ZLib, LZ4 -->
<CompressionType value="CompressionType::None"/>
<GuaranteedOutputBuffers value="5000"/>
<!-- ConnectionPingTimeout is optional: defaulted to 30000 -->
<ConnectionPingTimeout value="30000"/>
<!-- TcpNodelay is optional: defaulted to 1 -->
<!-- possible values: 1 (tcp_nodelay set), 0 (not set) -->
<TcpNodelay value="1"/>
<Host value="prod_ads1"/>
<Port value="14002"/>
</Channel>
<Channel>
<Name value="Channel_2"/>
<ChannelType value="ChannelType::RSSL_SOCKET"/>
<CompressionType value="CompressionType::None"/>
<GuaranteedOutputBuffers value="5000"/>
<Host value="prod_ads2"/>
<Port value="14002"/>
</Channel>
</ChannelList>
</ChannelGroup>
Above, we have two Channel configurations - both of type RSSL_SOCKET, one connecting to 'prod_ads1' and the other to 'prod_ads2'. If you refer back to our Consumer configurations, Consumer_1 specified Channel_1 for its Channel value:
...
<Name value="Consumer_1"/>
<Channel value="Channel_1"/>
...
So, if you were to specify Consumer_1 when creating our OmmConsumerConfig, EMA would attempt to connect to 'prod_ads1'. Since Consumer_1 is the default Consumer, you wouldn't actually need to specify it explicitly.
C++: config = OmmConsumerConfig(); // User default Consumer
Java: config = EmaFactory.createOmmConsumerConfig(); // Use default Consumer
However, as I mentioned earlier it is recommended practice to use a ChannelSet and specify more than one data source for failover purposes. Therefore, with the above particular config it would be better to use Consumer_2 :
C++: config = OmmConsumerConfig().consumerName( "Consumer_2" );
Java: config = EmaFactory.createOmmConsumerConfig().consumerName("Consumer_2");
Now, EMA will attempt to connect to 'prod_ads1', but if that server is down, then it will try and connect to 'prod_ads2'. Once you successfully connect, if at some later time the server goes down, EMA will automatically try and connect to the other server.
Using ChannelSets with Refinitiv Real-Time Optimized Cloud-based Services
As mentioned earlier, for our cloud-based service such as Refinitiv Real-Time Optimized (RRTO) - it is better to use the Session management feature and allow EMA to determine which endpoint to connect to - rather than hardcoding endpoints as the host value in the config. However, the following points are worth noting:
- You can use Service Discovery with ChannelSets by specifying different regions for the “Location” parameter in each channel in your ChannelSet e.g. eu-west, us-east or ap-southeast - to benefit from cross-regional resiliency.
- IF you do decide to use specific host endpoint values, you should pick 'standard' (Refinitiv Managed) endpoints in different regions e.g. apac-3-t2.streaming-pricing-api.refinitiv.com and emea-3-t2.streaming-pricing-api.refinitiv.com for each channel in your ChannelSet (to benefit from cross-regional resiliency).
You can read more about the various endpoints/regions/service levels for RRTO in the Refinitiv Real-Time - Optimized Install and Config Guide
There are various other parameters such as CompressionType and TcpNodelay - which are described in more detail in the EMA Config Guides (links at the start of the article).
Dictionary Types
There are two Dictionary types that can be specified for use by a Consumer configuration. A Channel Dictionary and File Dictionary. Once again we have a Group which contains a List with two configurations:
<DictionaryGroup>
<DictionaryList>
<Dictionary>
<Name value="Dictionary_1"/>
<!-- dictionaryType is optional: defaulted to ChannelDictionary" -->
<!-- possible values: ChannelDictionary, FileDictionary -->
<!-- if dictionaryType is set to ChannelDictionary, file names are ignored -->
<DictionaryType value="DictionaryType::ChannelDictionary"/>
</Dictionary>
<Dictionary>
<Name value="Dictionary_2"/>
<DictionaryType value="DictionaryType::FileDictionary"/>
<!-- dictionary names are optional: defaulted to RDMFieldDictionary and enumtype.def -->
<RdmFieldDictionaryFileName value="./RDMFieldDictionary"/>
<EnumTypeDefFileName value="./enumtype.def"/>
</Dictionary>
</DictionaryList>
</DictionaryGroup>
If you refer to our earlier Consumer configurations, Consumer_1 specified Dictionary_1 and Consumer_2 referenced Dictionary_2.
So, if the application uses the default Consumer_1 then EMA will request the dictionary from the server and download it. If however, the application uses Consumer_2 then EMA will expect to find the two files RDMFieldDictionary and enumtype.def in your application's working directory.
As you can see from the comments in the xml, EMA continues to implement Default behaviour wherever possible e.g. defaulting to ChannelDictionary and the filenames if they are not specified.
Logger Configuration
EMA C++ Logging
For EMA C++ it is also possible to configure Logging behaviour via the EMAConfig.xml file. If you refer back to the Consumer configurations you will see that Logger_1 and Logger_2 were specified for Consumer_2 and Consumer_1 respectively which are defined as follows:
<LoggerGroup>
<LoggerList>
<Logger>
<Name value="Logger_1"/>
<!-- LoggerType is optional: defaulted to "File" -->
<!-- possible values: Stdout, File -->
<LoggerType value="LoggerType::Stdout"/>
<!-- LoggerSeverity is optional: defaulted to "Success" -->
<!-- possible values: Verbose, Success, Warning, Error,NoLogMsg -->
<LoggerSeverity value="LoggerSeverity::Success"/>
</Logger>
<Logger>
<Name value="Logger_2"/>
<LoggerType value="LoggerType::File"/>
<!-- FileName is optional: defaulted to "emaLog_<process id>.log" -->
<FileName value="emaLog"/>
<LoggerSeverity value="LoggerSeverity::Success"/>
</Logger>
</LoggerList>
</LoggerGroup>
Based on the above Logger configuration, using Consumer_1 will result in output to a file and Consumer_2 will output to the console.
EMA Java Logging
As mentioned in the EMA Java Developer guide, EMA Java uses the popular SL4J logging API to provide considerable flexibility in which logging system to using. You can find further details on how to control the logging in a post on our developer forums - EMA Java Logging.
XML Trace
In addition to the Logger output, you can also configure EMA to trace the incoming and outgoing messages between your application and the server. I find this particular feature is incredibly useful for debugging if I have concerns about data at the application level. Since the trace is generated at a lower level, you can confirm with a high degree of confidence if the correct data is being sent or received on the wire. Therefore, if the data looks correct in the trace file but incorrect in your application then you can be reasonably sure the problem lies at the application level.
The trace is output in an XML format and is controlled using the XmlTrace related parameters.
EMA Java has one parameter - XmlTraceToStdOut - which enables (1) or disables (0) tracing to stdout. You can then use standard Java functionality to redirect the stdout output to a file if required. See this post on our developer forum for further details.
EMA C++ has a few more parameters related to XmlTrace - a few of the key ones are as follows:
| Parameter | Default | Description |
|---|---|---|
XmlTraceToFile |
0 | Enable (1) / disable (0) Tracing messages to file |
XmlTraceToStdout |
0 | Enable / disable Tracing messages to stdout |
XmlTraceFileName |
EmaTrace |
Name of trace file if enabled |
XmlTraceMaxFileSize |
100000000 |
Maximum size (in bytes) for the trace file |
XmlTraceToMultipleFiles |
0 | Enable / disable writing to new file if max file size reached |
There are a few other XmlTrace parameters (detailed in the EMA C++ Config guide - Consumer Entry parameters section) which allow finer control of the output e.g. trace only incoming or outgoing data.
Other Tuning Parameters
In addition to the above mentioned parameter settings, there are many other parameters which allow you to tweak things like timeout values, Buffers, Reconnect attempts etc. Please refer to the EMA Java or EMA C++ Config guides for further details.
Programmatic Configuration via OmmConsumerConfig::config()
The third option for overriding the defaults is available in all versions of EMA C++ and was added to EMA Java v1.2.1.
Programmatic configuration allows the developer to create an OMM based structure to override the defaults, and then pass it to the OMM Consumer. Note that Programmatic Config will override any values specified in the EMAConfig.xml file.
This is achieved by creating a hierarchical structure of OMM containers to represent the Groups, Lists and Parameter + values similar to the Xml format of the EMAConfig.xml file as illustrated below:
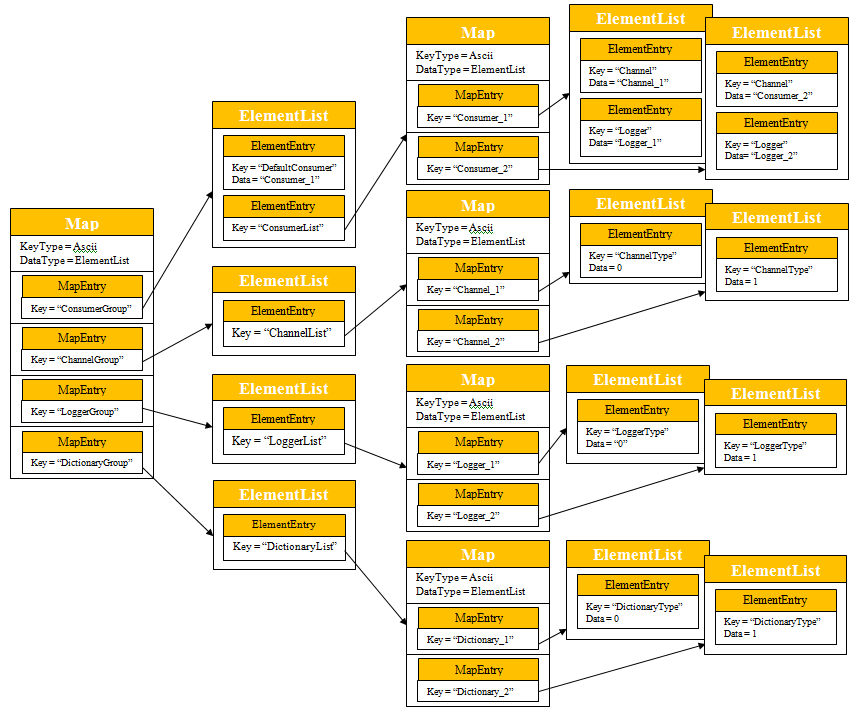
Once the OMM Map structure has been created it can then be passed to the OmmConsumerConfig object using the config() method.
This technique is demonstrated in the 421__MarketPrice__ProgrammaticConfig example that comes with the Refinitiv Real-Time SDK and I include a few snippets of the C++ version's code below.
The first snippet covers the populating of the OMM Map structure:
void createProgramaticConfig( Map& configMap )
{
Map innerMap;
ElementList elementList;
elementList.addAscii( "DefaultConsumer", "Consumer_1" );
innerMap.addKeyAscii( "Consumer_1", MapEntry::AddEnum,
ElementList()
.addAscii( "Channel", "Channel_1" )
.addAscii( "Logger", "Logger_1" )
.addAscii( "Dictionary", "Dictionary_1" )
...
...
.addUInt("MsgKeyInUpdates", 1).complete() ).complete();
elementList.addMap( "ConsumerList", innerMap );
elementList.complete();
innerMap.clear();
configMap.addKeyAscii( "ConsumerGroup", MapEntry::AddEnum, elementList );
elementList.clear();
innerMap.addKeyAscii( "Channel_1", MapEntry::AddEnum,
ElementList()
.addEnum( "ChannelType", 0 )
...
...
.addAscii( "Host", "localhost" )
.addAscii("Port", "14002" )
.addUInt( "TcpNodelay", 0 ).complete() ).complete();
elementList.addMap( "ChannelList", innerMap );
elementList.complete();
innerMap.clear();
configMap.addKeyAscii( "ChannelGroup", MapEntry::AddEnum, elementList );
elementList.clear();
...
...
configMap.complete();
}
A summary of the above snippet:
- Consumer_1 is specified as the Default Consumer
- Consumer_1 is defined along with its parameter values such as Channel, Dictionary etc
- Consumer_1 is added to the ConsumerList
- ConsumerList is added to ConsumerGroup
- Channel_1 is defined along with its parameter values such as Host, Port etc
- Channel_1 is added to ChannelList which is added to ChannelGroup
- The outer Map is finalised
I have left out a lot of the parameters and also the Dictionary and Logger related code for brevity - you can find the full code in the example 421 mentioned above.
Once we have the Map structure we can then pass it to the OmmConsumerConfig object - before using it to initialise the OmmConsumer object.
int main( int argc, char* argv[] )
{
...
Map configMap;
// Populate OMM Map structure with config parameters
createProgramaticConfig( configMap );
OmmConsumer consumer( OmmConsumerConfig().config( configMap ) );
...
}
In summary, the above snippet:
- Creates a Map object
- Calls the above createProgramaticConfig() method to populate the Map with the config structure
- Passes the Map to the OmmConsumerConfig object using the config() method
- Initializes the OmmConsumer with the configuration
Just to be clear, the OmmConsumerConfig::config() method 'specifies the local configuration, overriding and adding to the current content'. Therefore, you only need to provide those groups, lists and parameters that you wish to override. So, for example if you are happy with the default Dictionary definitions or Logger definitions, then you don't need to add them to your Map structure.
This also means that you could specify the bulk of your (rarely changing) configuration in the EMAConfig.xml file and then only override a limited set of parameters programmatically as and when required.
OmmProvider Configuration
I have have focused on OmmConsumer configuration, however, OmmProvider configuration works much in the same way - i.e. default behaviours, which can be overridden via the EmaConfig.xml file (and/or programmatically).
Closing notes
I hope this article has been useful; if I did not cover a particular question you may have, it may have been asked and answered over on our Developer forums - EMAConfig related questions.
If not please go ahead and post your question on the EMA Forum.
Additional Resources
You will also find links to the Tutorials and SDKs in the Links Panel.