
Automating a Large Binary Result with Postman

Introduction
In this article let us discuss a very attractive use case of automating the downloads of very large binary files with Postman. Per Postman guidance on the large file downloads, for the files that are larger then 100 MB, "Send and Download" option is recommended. This option is manual, i.e. precludes automation via Postman scripting. And there is a limit to the size of the file that one can download with Postman, even with "Send and Download". At the time of this writing, this unoffical limit is not quite large enough to support the requesting of the larger content results that are available out there. For files and results that are large, but not oversized- one can progress by manually partitioning the result, into confortable partitions of 200MB or so- see Downloading a Large Tick History Extraction Result - with Postman. However, when we are looking at the requirement to create more then just a few partitions, each of which will need to be downloaded manually, this is where using Postman scripting to automate the process becomes a really attractive approach, that is worth a closer look.
An excellent option is available from Postman team off-the-shelf for downloading and savind text/ascii content, it is Writing Response To File example. This example covers CSV, JSON, and can be adapted for other text or semi-text content. However, some of the truly large result sets out there are made available as true binary, as they are the large text content sets, that are zipped.
We are going to adapt Writing Response to File and try to take it further- into the large binary territory.
Going to use the latest version of Postman and NodeJS. The scripts discussed are made available via Refinitiv GitHub samples space, please see References section at the end for the links to download.
Example Use Case
As an example use case we are going to use a normalized zipped file, that carries over 1GB of data, to be precise 1227274223 bytes. A different binary file of similar size can be approached in exact same way. This specific file is a Refinitiv Data Platform, Client File Store, Tick History File "LSE-2021-12-29-NORMALIZEDMP-Data-1-of-1.csv.gz" and carries the whole day of exchange data for LSE exchange.
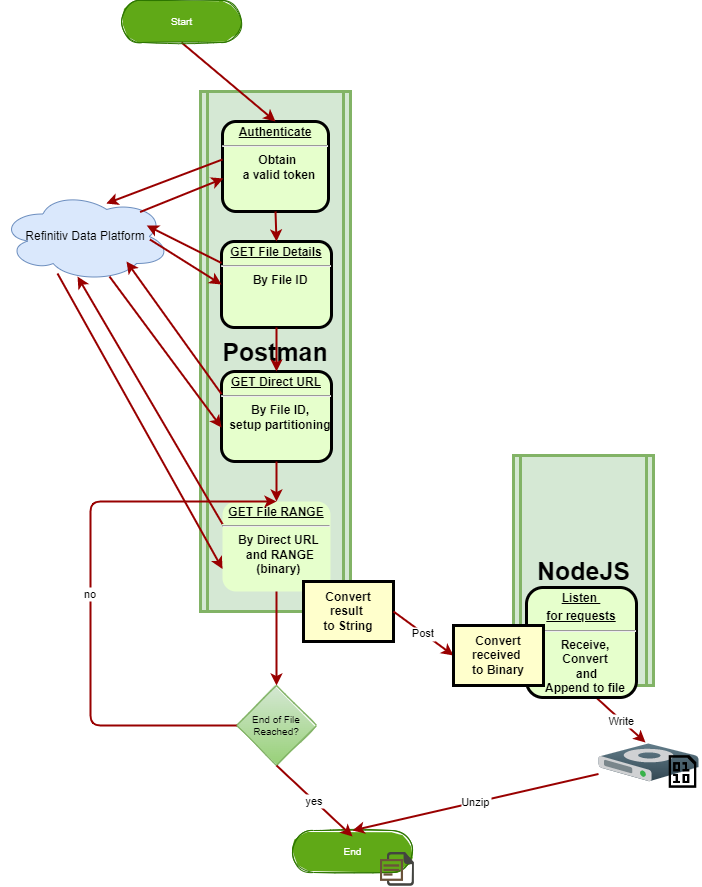
Our steps for the complete CFS-specific processing will be:
- Authenticate with Refinitiv Data Platform
- Obtain the file size of the file to be requested <For this and the next steps, Postman Collection Runner is used to automate>
- Obtain the direct URL to AWS to be accessed
- Iteratively process requests via direct URL
- Postman test script sets up Range to request the specific portion of the result
- Postman test script uses btoa() to convert a portion of the binary result into base64-encoded ascii
- Postman test script posts the portion of the file to NodeJS to be stored to disk
- NodeJS script uses atob() to turn base64-encoded ascii data back to binary
- NodeJS appends the converted to the file on disk
- Postman test script self- points back for the next iteration, having updated Range variable <end of Postman Collection Runner steps>
- The total binary result that is assembled at this point can be unzipped, and next it is ready to be used per requirements at hand.
In the next discussion we focus on the step 4 as it implements the general approach to large binary file request automation with Postman scripting.
Let us examine the approach:
Get TH File Details by File ID Very Large File
In Get TH File Details by File ID Very large File request, in Tests, from the response we parse out the size of the file to be requested and store it into the environment:
var jsonData = JSON.parse(responseBody);
pm.collectionVariables.set("fileSizeInBytes", jsonData.fileSizeInBytes);
Get TH File by File ID Location (No Redirect) Very Large File
In Get TH File by File ID Location (No Redirect) Very Large File, in Tests we setup for the first round of iterative processing by defining and storing into Postman environment:
- rangeStart
- rangeEnd
- rangeChunk
Our ideal chunk is not the exact science, and I would expect that the best suited chunk size or partition size may differ from environment to environment. At the time of this writing, in my local test environment, 100 MB is the largest that is processed consistently and safely, without request failures, transfer failures or Postman crushes. In the code we leave an easy option to tune it up when an opportunity presents itself, or to size it down, if need be.
var jsonData = JSON.parse(responseBody);
pm.collectionVariables.set("responseUrl", jsonData.url);
postman.setEnvironmentVariable("responseUrl", jsonData.url);
pm.collectionVariables.set("rangeStart", 0);
pm.collectionVariables.set("rangeChunk", 100000000);
//pm.collectionVariables.set("rangeChunk", 200000000);
pm.collectionVariables.set("rangeEnd", (pm.collectionVariables.get("rangeStart") +pm.collectionVariables.get("rangeChunk") -1));
Get TH File by direct URL- Very Large File
And now we are ready to get our file by portions, step 4 above. In Pre-Request script we will refine Range via rangeStart and rangeEnd variables:
pm.request.headers.add({
key: 'Range',
value: 'bytes='+pm.collectionVariables.get("rangeStart")+'-'+pm.collectionVariables.get("rangeEnd")
Our request is simply GET on response URL, and our Tests script is where the main action is taking place:
// PREPARE FOR THE NEXT ITERATION
console.log("Just obtained: ",pm.collectionVariables.get("rangeStart")+ "-"+ pm.collectionVariables.get("rangeEnd")+" out of "+pm.collectionVariables.get("fileSizeInBytes"));
pm.collectionVariables.set("rangeStart", (pm.collectionVariables.get("rangeStart") + pm.collectionVariables.get("rangeChunk")));
pm.collectionVariables.set("rangeEnd", (pm.collectionVariables.get("rangeStart") +pm.collectionVariables.get("rangeChunk") -1));
if (pm.collectionVariables.get("rangeStart") <= pm.collectionVariables.get("fileSizeInBytes") ){
if (pm.collectionVariables.get("rangeEnd") > (pm.collectionVariables.get("fileSizeInBytes") -1)) {
pm.collectionVariables.set("rangeEnd", (pm.collectionVariables.get("fileSizeInBytes") -1));
}
console.log("Setting up for the next iteration: "+ pm.collectionVariables.get("rangeStart")+ "-"+pm.collectionVariables.get("rangeEnd"));
postman.setNextRequest("Get TH File by direct URL- Very Large File");
} else {
console.log("this was the last request")
postman.setNextRequest(null);
}
console.log('pm.response.responseSize='+pm.response.responseSize)
// SEND THE PARTION TO NODE JS
setTimeout(() => {
pm.sendRequest({
url: 'http://localhost:3000/write',
method: 'POST',
header: {
'Content-Type': 'application/octet-stream'
},
// encoding: 'binary',
body: {
mode: 'raw',
raw: btoa(pm.response.stream)
}
}, function (err, res) {
console.log(res);
});
}, 50000);
Node.js Script
Now late us see what is taking place on the other side, when we run:
node script.js
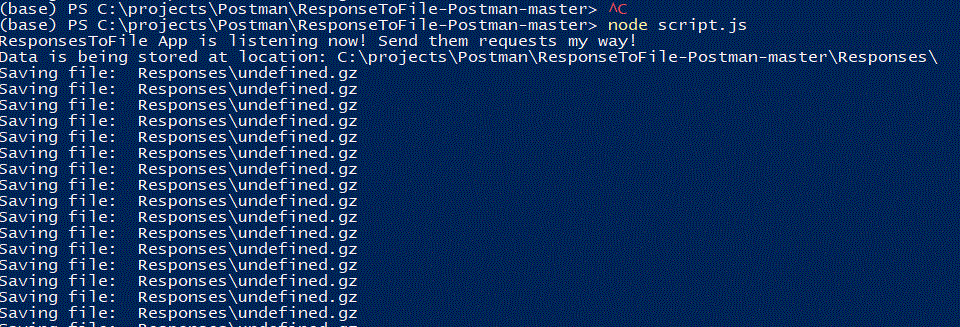
we are receiving, converting and appending partitions of our large result, via script:
...
app.get('/', (req, res) => res.send('Hello, I write data to file. Send them requests!'));
app.post('/write', (req, res) => {
let extension = req.body.fileExtension || defaultFileExtension,
fsMode = req.body.mode || DEFAULT_MODE,
uniqueIdentifier = req.body.uniqueIdentifier ? typeof req.body.uniqueIdentifier === 'boolean' ? Date.now() : req.body.uniqueIdentifier : false,
filename = 'downloadedFile'
filePath = `${path.join(folderPath, filename)}.${extension}`,
options = req.body.options || undefined;
console.log('Saving file: ',filePath);
fs[fsMode](filePath, atob(req.body), 'binary', (err) => {
...
Postman Collection Runner
Postman Collection Runner is how we are going to run our collection Very Large RDP CFS TH File automatically.
The first two requests will run once, and the third one will call itself recursively, per Tests script, walking through Range as required:

or "Run Collection" as the separate little collection is available for download on GitHub ( see References section). Once it is running, the output should look like this:
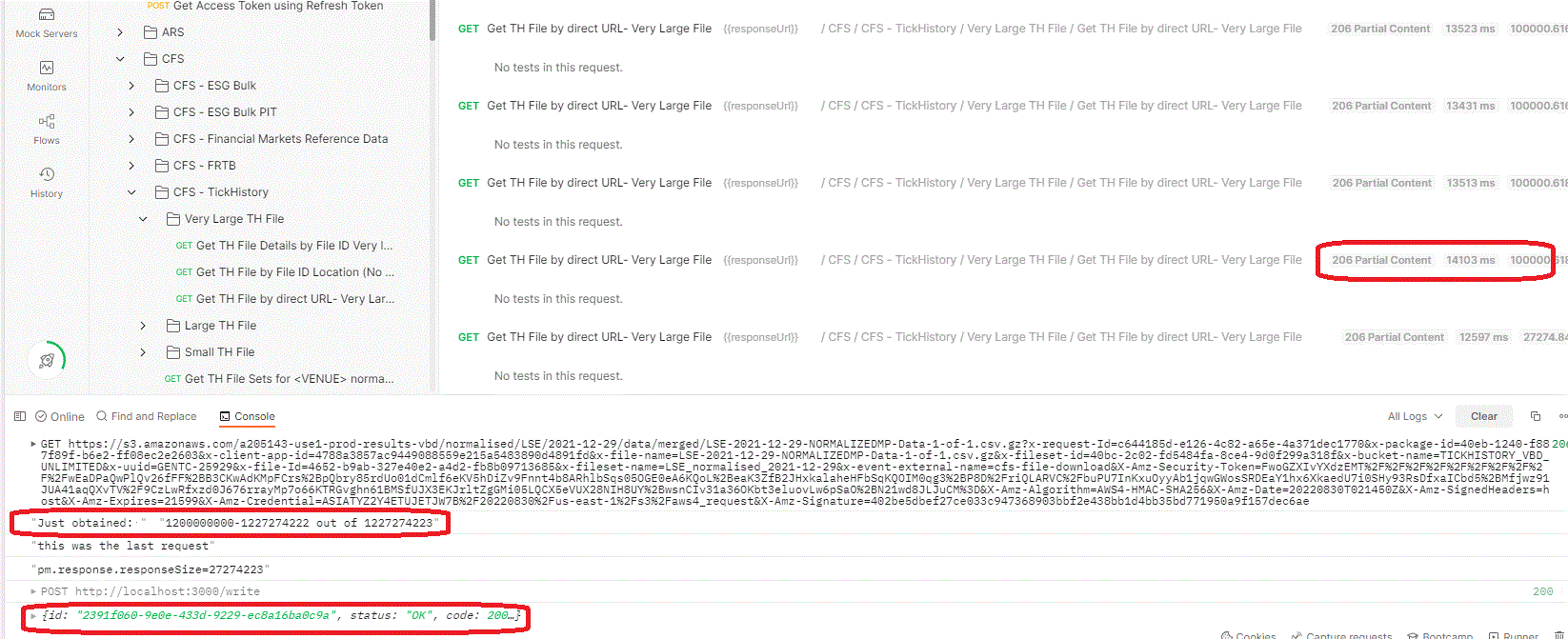
each successful iteration resulting in OK acknowledgment from Node.js. The file on the disk should be created ( it teh file exists already, should be removed prior to the run) in the same folder where Node.js script is running, and should grow roughly at the increments of 100Mb. At the end, the complete zipped file should be received and stored :
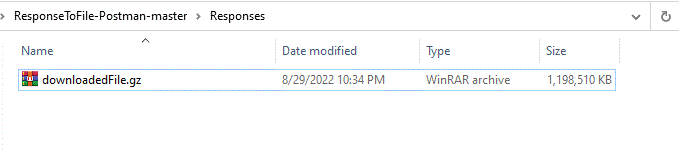
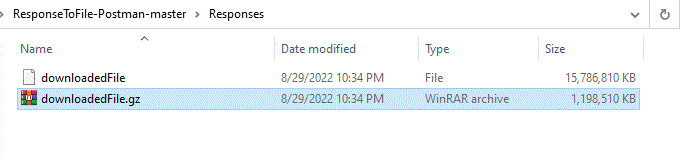
and once we unzip it:
We have described the approach to large binary file downloading with Postman, from our testing, it can be applied to files up to about 1.5GB. We hope that you have found this discussion useful.
With questions, comments and the next topics suggestions for developer advocacy materials- look us up on Refinitiv Developers Forums
References
GitHub Refinitiv-API-Samples/Article.Postman.AutomatingALargeBinaryResult
Refinitiv Data Platform APIs | Refinitiv Developers
Postman- Writing Response To File
Downloading a Large Tick History Extraction Result - with Postman