
Introduction
Identifying financial entities is quite a challenging task when designing applications that aggregate content from different vendors.
There are several ways of identifying a financial instrument that largely vary on the scope of the standard that describes them. There are international, local, trading venue specific and proprietary codes.
For instance, the below codes are assigned to Apple Inc., an American technology giant, and its ordinary shares:
| Scheme | Code | Scope |
| LEI | HWUPKR0MPOU8FGXBT394 | International |
| Business register | RA000598 | National, United States |
| ISIN | US0378331005 | International |
| SEDOL | 2046251 | National, United Kingdom and Ireland |
| CUSIP | 37833100 | National, United States |
| Valor | 908440 | National, Switzerland |
| Ticker | AAPL | Exchange-specific |
| RIC | AAPL.O | Quote-level, proprietary |
If you are an Eikon or Refinitiv Workspace user, type in AAPL.O CODES into the command bar, press Enter, and you will see something like this:
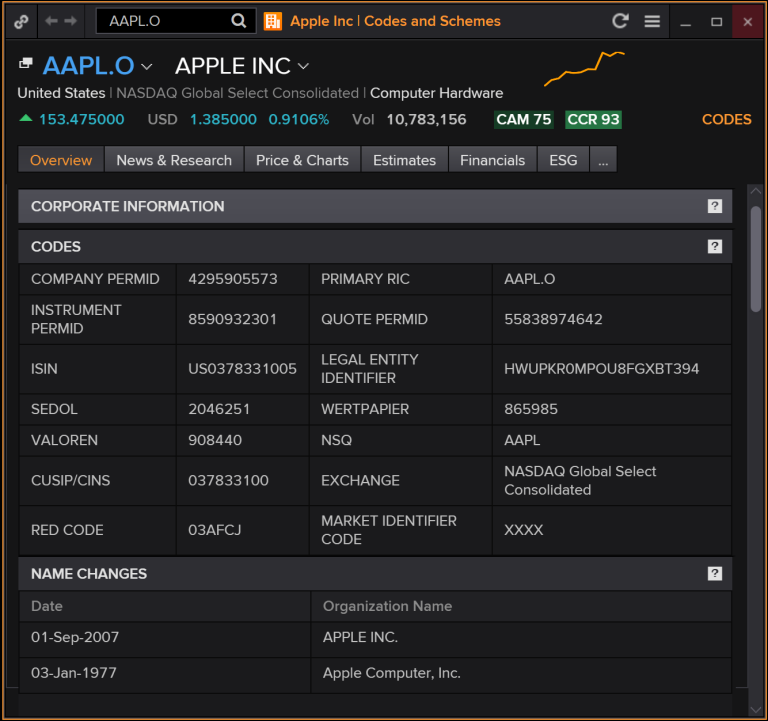
You have probably noticed that there is also another coding scheme that I have not mentioned yet, but it is on the screenshot, Refinitv Permanent Identifier or, simply, PermID.
So, what is PermID?
PermID is an open unique identifier developed by Refinitiv. Technically it is a 64-bit number that we use to identify different kinds of objects, for example:
| Type | PermID | Label |
| Organization | 4295905573 | Apple Inc. |
| Instrument | 8590932301 | Apple Ordinary Shares |
| Asset class | 300281 | Ordinary Shares |
| Quote | 55838974642 | Apple Ordinary Shares, NASDAQ |
| Person | 34413400240 | Craig Federighi |
| Currency | 500110 | USD |
| Industry code | 4294952723 | Economic Sector: Technology |
PermIDs are distributed through permid.org where you can download the whole dataset as a series of flat files (n-triples, turtle formats) or use one of the APIs that is most suitable for your needs.
I am going to show how to use the matching functionality in Python.
PermID API
In order to run the code samples, you will need to obtain an API key either through the Developer Community portal or by registering at permid.org.
Record matching API
In order to use the record matching API, we need to create a standard CSV file for input. Since in this example we will be matching organizations, here is what the template will look like:
| LocalID | Standard Identifier | Name | Country | Street | City | PostalCode | State | Website |
| 1 | Ticker:AAPL&&MIC:XNGS | |||||||
| 2 | LEI:549300561UZND4C7B569 |
As you can see, we can use some standard identifiers such as Ticker + MIC, LEI, etc.
This is how we will create our request, assuming that input.csv contains the above table:
url = 'https://api.thomsonreuters.com/permid/match/file'
headers = {
'x-ag-access-token':'your_access_token',
'x-openmatch-numberOfMatchesPerRecord':'1',
'x-openmatch-dataType':'Organization',
'Accept':'application/json'
}
with open('input.csv', 'rb') as input_file:
content = input_file.read()
files = {'file': ('input.csv', content, 'application/vnd.ms-excel')}
response = requests.post(url=url, headers=headers, files=files)
Let's dump the results
data = json.loads(response.text)
if result:
header_list = list((result[0]).keys())
writer.writerow(header_list)
for item in result:
writer.writerow(list(item.values()))
After running the tool, you should be able to see this:
Uploaded filename: input.csv
Request time: 168 ms
Status: Success
Number of received records: 9
Number of processed records: 9
Number of error records: 0
Number of unmatched records: 0
Number of matched records, total: 9
Result
With these results you can easily build a console tool, as well as integrate matching into your data mapping pipeline.