
The Enterprise Message API (EMA) is a high-level API for consuming and publishing real-time streaming data from and to our data distribution Platform - Refinitiv Real-time. It is also the recommended API for the majority of developers wishing to consume real-time data from our Refinitiv Real-Time feeds.
EMA is part of the Refinitiv Real-Time SDK which also includes the Enterprise Transport API (ETA). ETA is the low-level API which is used internally by Refinitiv to develop the above Refinitiv Real-time components. Whilst ETA can be used to develop your own applications, this is usually only for those applications that require the lowest possible latency and highest throughput. For most use cases, however, EMA will be the most appropriate choice. Why is this?
Ease of use
First and foremost, EMA is an easy to learn and easy to use, high level, high performance, open-source extensible API that operates at the Message layer. In other words, the developer generally only needs to deal with Data and Status messages.
It achieves the ease of use by abstracting away the complexities and adding capabilities on top of the Transport layer.
EMA further reduces coding effort by defaulting much of the behaviour, thereby saving the developer the need to implement much of the code required for the most common usage scenarios. For example, requesting a data item can be done in a single line of code, as EMA defaults to a streaming (tick by tick) request for the most common Market Price data model. However, it continues to offer a high degree of flexibility by allowing the developer to override the default behaviour – should finer control be required for particular use cases.
It delivers all this whilst continuing to offer high performance and low latency processing of the requested streaming data. The open-source version is available on GitHub and the official Refinitiv supported version is available on this Developer Portal (see links to the right).
Consumers and providers
As well as developing consumer applications to request data, EMA can also be used to publish data for consumption by others, both internal and external consumers. For internal consumers, you would typically use our provider classes to publish your internally generated data to your Refinitiv Real-Time Distribution system (formerly know as TREP). Consumers would then be able to consume the data in a similar manner to the Refinitiv Real-Time feed data feeds. Providers can be implemented in the following modes:
- interactive: only provide the instruments requested by consumers;
- non-interactive: provide all instruments regardless of whether anyone is currently interested.
You may wish to use the interactive mode when you have a huge universe of instruments and know that only a limited set will likely be consumed at any given time.
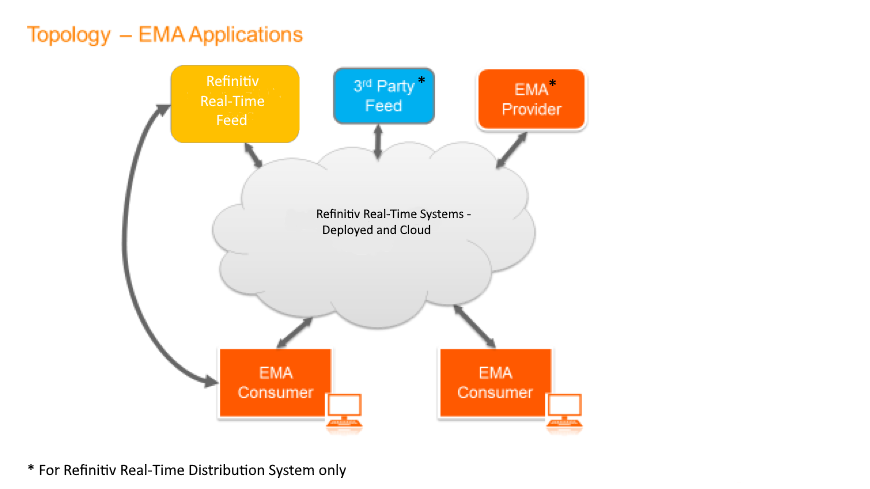
To distribute data to external consumers, EMA offers the posting functionality, whereby your application can send data to a contribution gateway which can then be sent onto Refinitiv or other third-party data vendor for incorporation into their feeds.
Consumer application life cycle
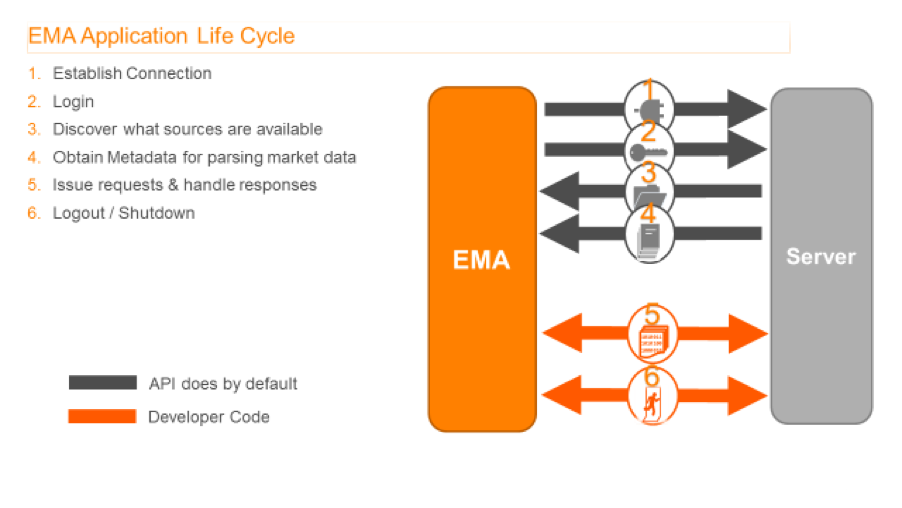
- Establish a connection to the data provider; developer needs to specify the hostname/ip address of where the provider is running and port number on which the Provider is accepting incoming requests – the API takes care of establishing the connection (and in case of failure scenarios the API also attempts recovery etc) behind the scenes.
- Log in: developer needs to provide user name, and the API attempts the login.
- Discover what sources of data are available on the connected server (the API does this behind the scenes).
- Obtain the metadata for parsing the received market data (API does this behind the scenes);
- Issue requests and handle data responses, developer needs to provide the code to make the request and implement callback handlers to process the responses.
- Logout and shutdown, a single line of code to dispose and clean-up.
Asynchrony
EMA helps you avoid performance bottlenecks and enhance the overall responsiveness with its asynchronous design using a callback mechanism.
EMA includes a consumer client class which provides a callback mechanism for EMA to send incoming messages to the application. As the developer you need to implement a class inheriting from this consumer client and define the callback methods to process the incoming messages.
When your application requests an instrument, it specifies the derived client class as the callback handler. By default, EMA takes care of dispatching the messages as they arrive and execution of the callback methods, both of which are done in EMA’s thread of control.
You can override this and let your application control the dispatching of the messages using the application thread. As a result the callback methods are also then executed using an application thread.
Interaction with the data provider
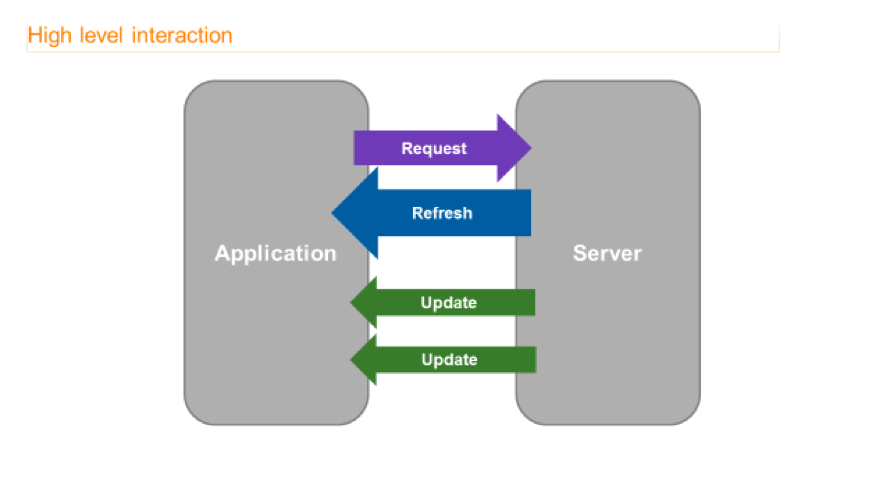
The above diagram represents a high level overview of the interaction between a consumer and a provider. Once your application has successfully established a connection and logged in to the server, it makes a request for one or more instruments.
For each valid request, your application will then receive a refresh response message which reflects the current market state for that instrument.
The refresh response message will contain a payload of the relevant data, so for a simple market price request you will receive a list of fields containing the price and other information. The refresh will contain every single possible field that relates to that instrument – even if that field is blank or empty at that moment in time.
Following the refresh response, your application will then receive the update response messages as and when there is any change to the market state for the instrument. Unlike the refresh message, the update typically only contains those fields that have changed since the refresh response or previous update response. So, for example if the bid price for an instrument changes, the bid size will normally change as well and therefore the update response message would contain both bid price and bid size fields with the updated values.
Data model
So, what kind of data can you consume using EMA?
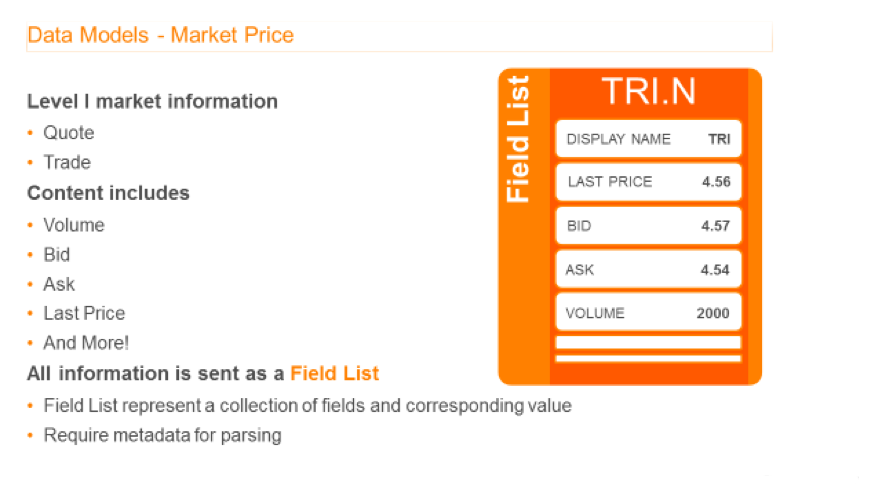
We previously spoke of the market price data, which is often referred to as Level 1 data, containing fields like bid, ask, volume, trade price and so on. It is delivered as a simple one-dimensional list of fields. The other thing to bear in mind is that a data dictionary is required in order to decode the data, which EMA downloads for the developer by default.
EMA can also consume more advanced content, such as the order book data, or Level 2. It can take two forms:
- depth of market, or market by price, which provides a view of the market ordered by price point i.e. number of orders at each price point for an instrument;
- full order book, or market by order, which is a list of all individual orders on the market for an instrument;
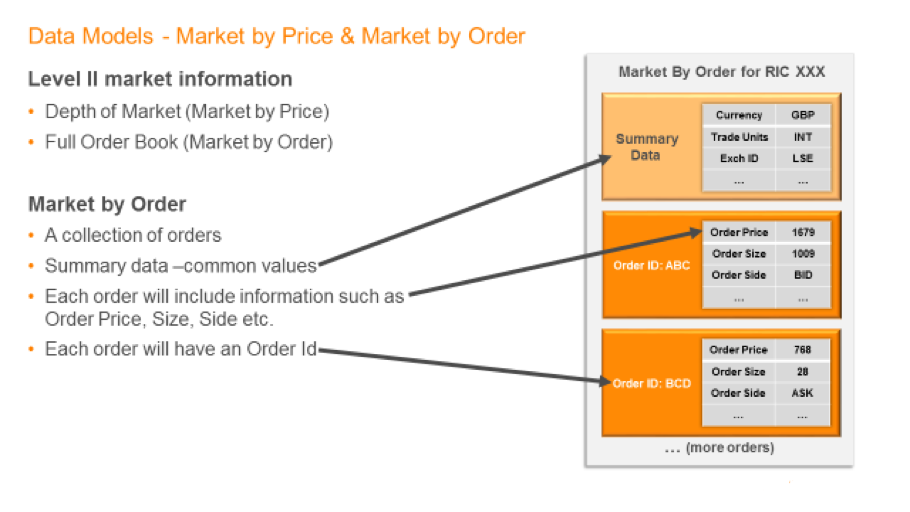
Due to the nature and quantity of data in a typical order book, using a one dimensional list of fields is not practical. Therefore, in order to represent the order book data, Refinitiv uses a collection where each item represents an order book entry.
So, for example if you make a market by order request for an instrument, the response message will contain a payload of a map container, where each map entry represents an individual order on the market for that instrument. Each of these order entries will contain a field list containing values like order price, size, side and so on.
In addition to the map container, the payload will also have a summary section which holds values that are common to the whole order book in order to minimize repetition of the common data.
Likewise for a market by price request, the response message will contain the summary section of the common values and a map container, where each map entry represents a price point for that instrument. Each entry will again contain a field list of values like order price, side, number of orders at that price point, etc.
Processing and extracting the order book from the message is relatively straightforward and we have a short tutorial that shows how to consume Level 2 data in the developer tutorial for Java and C++ versions (see links on the right of this article).
Other features
EMA offers additional feature and functions to make a developer life easier. A few examples of these are:
- batch requests, a single request message to get multiple instruments;
- snapshot requests, a non-streaming request, where you receive the initial refresh response with no subsequent updates;
- pause and resume data streams, a more efficient way of managing streams;
- horizontal scaling, the ability to spread the processing of message across multiple threads and thereby multiple cores.
These and additional features are covered by the comprehensive set of sample applications that are included in the EMA package.
Conclusion
If you are planning to develop a new app or upgrade an existing legacy solution in C++ or Java, to
- Consume or Publish data using the Refinitiv Real-Time Distribution System – whether that is Refinitiv Real-Time data, third party data or internally generated data
- Consume data from the Cloud-based Refinitiv Real-Time offerings
- Contribute data to the Refinitiv Contribution Channel.
the Enterprise Message API should be at the top of your list. It's easy to learn, quick to implement, with simpler long term maintenance whilst offering a level of performance suitable for most scenarios.
Additional Resources
You will find links to the APIs, Related Articles and Tutorials in the Links Panel